【python】畳み込みニューラルネットワークによる画像判別プログラムの開発
畳み込みニューラルネットワーク(Convolutional Neural Network, CNN)は、画像認識や物体検出などのコンピュータビジョンタスクに広く使用されるディープラーニングの一種です。
CNNは、局所的な特徴を捉える能力とパラメータの共有による計算効率が高い点が特徴です。
本記事では、CNNの基本概念やアーキテクチャ、学習方法、応用例について説明します。
畳み込みニューラルネットワーク|CNN(Convolutional Neural Network)
CNNは複数の層からなるニューラルネットワークの一つです。
CNNは、以下のような実践的なコンピュータビジョンタスクに広く適用されています。
画像分類(Image Classification):画像に含まれる主要な物体のカテゴリを予測するタスクです。
例えば、犬や猫の画像を分類することができます。
物体検出(Object Detection):画像内の物体の位置(境界ボックス)とカテゴリを同時に予測するタスクです。
YOLOやSSDなどのアーキテクチャが有名です。
セマンティックセグメンテーション(Semantic Segmentation):画像内の各ピクセルにカテゴリラベルを割り当てるタスクです。
U-NetやFCN(Fully Convolutional Network)などのアーキテクチャが知られています。
下の画像のように、畳み込み層とプーリング層などの層があります。
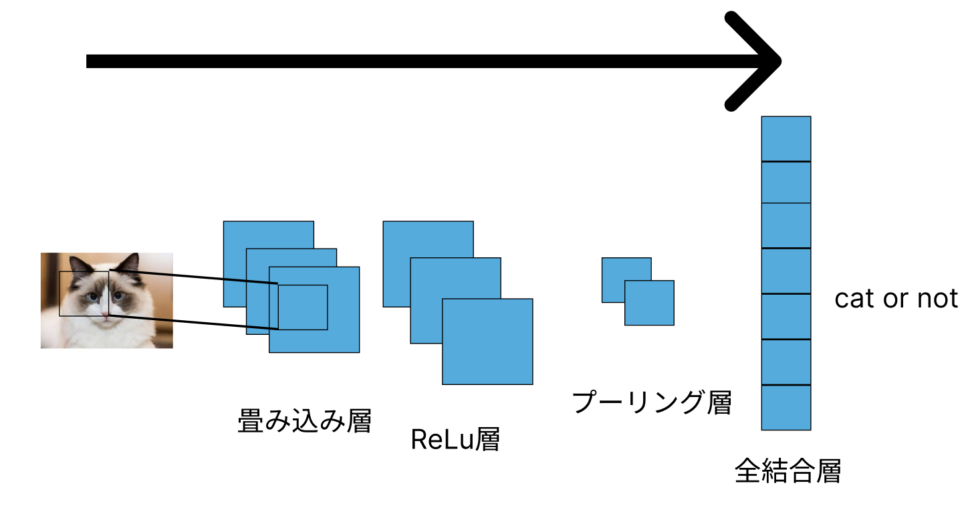
畳み込み層は、CNNの基本要素であり、入力画像の局所的な特徴を捉えるために使用されます。
フィルター(またはカーネル)と呼ばれる小さなウィンドウを用いて、入力画像上をスライドさせながら局所的な特徴を抽出します。
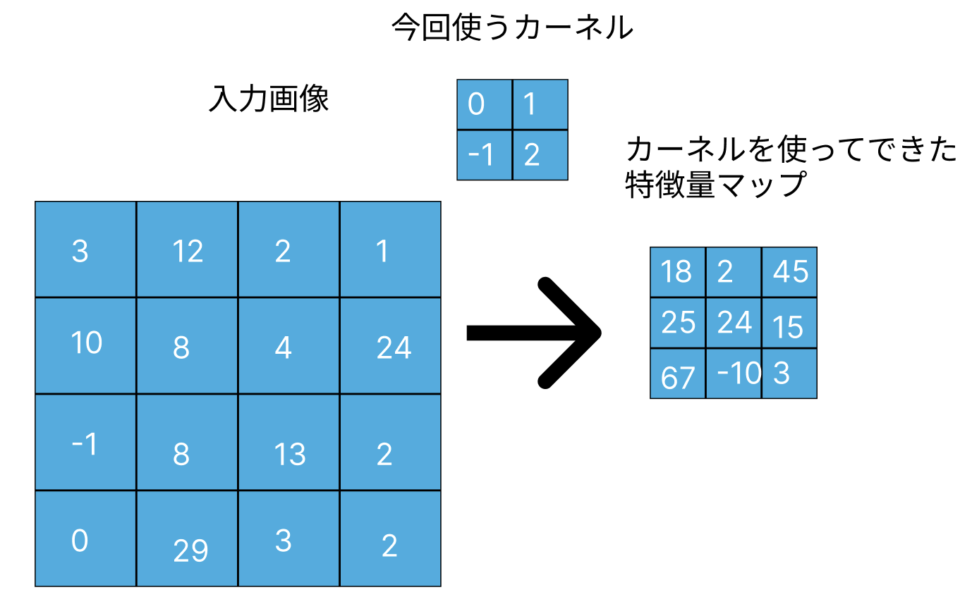
畳み込み演算では、フィルター内の各要素と対応する入力画像の要素の積を計算し、それらの和を求めます。
フィルターと入力画像の要素の積は内積です。
これをフィルターが画像上をスライドするたびに繰り返し、新しい特徴マップが生成されます。
カーネルを通して、新しい特徴マップを作ったことでもとの画像に比べて少し小さくなることがわかったでしょうか
これが畳み込みの所以です。
畳み込み層の出力 \(y_{i,j}\) は以下の式で表されます。
ここで、\(w_{m,n}\) はフィルターの重み、\(x_{i+m, j+n}\) は入力画像の要素、\(b\) はバイアス、\(f\) は活性化関数です。
$$y_{i,j}=f(\sum_{m}\sum_{n}w_{m,n}x_{i+m,j+n}+b)$$
畳み込み層は人間の目にある「局所受容野」と同じような働きをします。
共通点はズバリ、「特徴を局所的な抽出」することです。
ある局所受容野は、例えば右から左へ流れる線を検出することはできても、他の構造や境界を検出することはできません。
様々な境界を検知できる局所受容野が存在することで、人間は外界をきちんと構造的に把握し、物体を区別できているというわけです。
プーリング層(pooling layer)
プーリング層は、畳み込み層で抽出された特徴マップの次元を削減するために使用されます。
一般的に最大プーリング(Max Pooling)または平均プーリング(Average Pooling)のいずれかを使用します。
最大プーリングは、ウィンドウ内の最大値を取得し、平均プーリングはウィンドウ内の平均値を取得します。
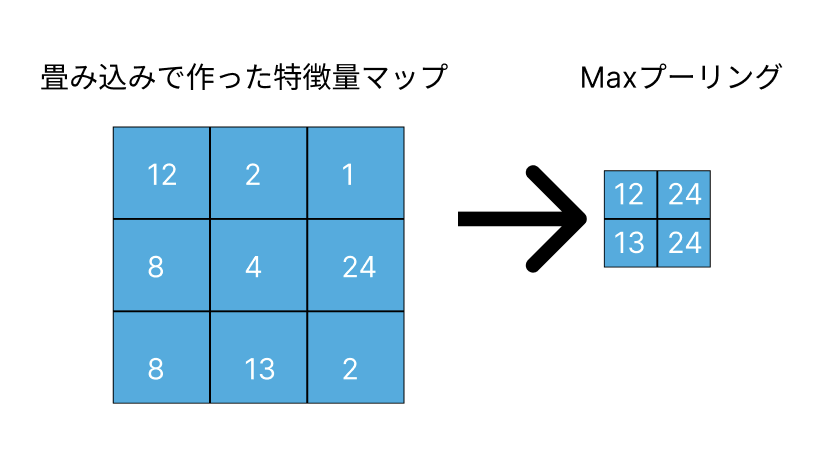
こんなことをしまっては、元々の画像の特徴が減っていくではないかとお想いになるかもしれません。
正解です。
ただ、画像の判別問題で言えば判別に重要な特徴以外の瑣末な情報を弾いているという、重要なプロセスです。
プーリング層の目的は、特徴マップのサイズを縮小し、計算量を削減するとともに、過学習を防ぐ効果があります。
また、位置に対するロバスト性も向上させます。
位置に対してロバストだと、被写体の角度や位置が多少ずれても、同じものだと検知できるという意味合いです。
ここまで難しく説明しましたが、CNNのメリットは行うかというと
①情報をなるべく失わずに圧縮する
②平行移動に対する頑健性(ロバスト性)を担保
③パラメータ数を削減する。
と考えていただければと思います。
③に関しては、畳み込み層では同じカーネルが画像全体に適用されるため、パラメータが共有されます。
これにより、ネットワークのパラメータ数が大幅に削減され、計算効率が向上します。
活性化関数|ReLu
上で表したように、活性化関数は、ニューラルネットワークの各層で出力を非線形に変換する役割を果たします。
非線形性がなければ、ニューラルネットワークは単なる線形変換の積であり、複雑な関数を学習することができません。
よく使用される活性化関数には、ReLU(Rectified Linear Unit)やシグモイド関数(Sigmoid)、Tanh(Hyperbolic Tangent)などがあります。
ReLuは以下の式で定義されます。
$$f(x)=max(0,x)$$
ReLUは、負の入力に対しては0を出力し、正の入力に対してはそのままの値を出力します。
これにより、勾配消失問題を軽減し、学習が速くなるという利点があります。
誤差逆伝播法と勾配消失問題について
CNNの学習は、一般的なニューラルネットワークと同様に、誤差逆伝播法(バックプロパゲーション)を用いて行われます。
バックプロパゲーションは、出力層から入力層に向かって、誤差の勾配を伝播させながら、各層のパラメータ(重みとバイアス)を更新していく方法です。
微分係数の最大値が0.25であるシグモイド関数(活性関数)に対して、ReLuの微分係数の最大値は1です
誤差逆伝播法を使う場合、誤差に微分係数をかけていきます。
シグモイド関数の場合、微分係数が最大だったとしても入力層に近いほど、勾配が小さくなっていくという「勾配消失問題」がおきます。
活性関数にシグモイド関数を使うとき、中間層が多すぎるとこの問題が起き、予測精度が上がらない+学習が終わらないなどの問題が生じます。
ゼロパディングとストライド
CNNのテクニックを2つご紹介いたします。
ゼロパディングは、入力画像の周囲にゼロ値のピクセルを追加することで、畳み込み層の出力サイズを調整するテクニックです。
ゼロパディングを使用することで、画像の端の情報が失われるのを防ぐことができます。
ストライドは、フィルターが画像上を移動する際のステップサイズを指します。
ストライドを大きくすることで、畳み込み層の出力サイズが小さくなり、計算量が削減されます。
CODE|python
プーリング層をどの大きさに設定するか、活性化関数は何にするか、など多くの部分を操作することができます。
精度を高められるように、工夫してみてください。
import tensorflow as tf
from tensorflow.keras import layers, models
# サンプルデータセット(CIFAR-10)の読み込み
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# 画像の正規化(0から1の範囲にスケーリング)
x_train, x_test = x_train / 255.0, x_test / 255.0
# CNNモデルの構築
model = models.Sequential([
# 畳み込み層(ゼロパディングあり、ストライド=1)
layers.Conv2D(32, (3, 3), padding='same', activation='relu', input_shape=(32, 32, 3)),
# プーリング層(ストライド=2)
layers.MaxPooling2D(pool_size=(2, 2), strides=2),
# 畳み込み層(ゼロパディングなし、ストライド=1)
layers.Conv2D(64, (3, 3), activation='relu'),
# プーリング層(ストライド=2)
layers.MaxPooling2D(pool_size=(2, 2), strides=2),
# 全結合層
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax')
])
# モデルのコンパイル
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# モデルの学習
model.fit(x_train, y_train, epochs=10, validation_split=0.2)
# モデルの評価
test_loss, test_acc = model.evaluate(x_test, y_test)
print('Test accuracy:', test_acc)
このコードは、CIFAR-10データセット(32×32ピクセルのカラー画像10,000枚)を用いて、ゼロパディングとストライドを含むCNNモデルを学習し、評価します。
畳み込み層とプーリング層が交互に配置され、最後に全結合層が続きます。
ゼロパディングはpadding='same'を指定することで実現され、ストライドはMaxPooling2D層のstrides引数で指定され
他の機械学習については以下のコンテンツをご覧ください。
【XGB】交差検証法を使った勾配ブースティング決定木の実装|python
【python】Ridge(リッジ)回帰で多重共線性を解決する話
【ランダムフォレスト】ブートストラップ法を決定木に応用|python
【判別問題】サポートベクトルマシン(SVM)の仕組み|python
【kaggle】ベイズ最適化とXGBでtitanicの予測問題を解く|python
補足:CNNのアーキテクチャの例
LeNet-5
LeNet-5は、Yann LeCunによって提案された最初の成功したCNNの一つであり、手書き数字認識を行うために設計されました。
畳み込み層とプーリング層を交互に配置し、最後に全結合層を持つ構造をしています。
AlexNet
AlexNetは、2012年のImageNet画像分類コンペティションで優勝したCNNであり、ディープラーニングのブームを引き起こしました。
LeNet-5と同様に、畳み込み層とプーリング層が交互に配置されていますが、より多くの層とパラメータを持っています。
また、ReLU活性化関数を使用して、学習の高速化と勾配消失問題の軽減を実現しています。
VGG-16
VGG-16は、2014年のImageNetコンペティションで高い評価を受けたCNNアーキテクチャです。
VGG-16は、3×3の小さなフィルターサイズを使用して、より多くの畳み込み層を持つことで、ネットワークの深さを増やしました。
畳み込み層のブロックとプーリング層で構成され、最後に全結合層が続きます。
ResNet
ResNet(Residual Network)は、2015年のImageNetコンペティションで優勝したCNNアーキテクチャであり、非常に深いネットワークを効果的に学習するための残差接続(Skip Connection)という技術を導入しました。
残差接続により、勾配消失問題が軽減され、より深いネットワークの学習が可能になります。
ResNetは、畳み込み層と残差接続で構成されたブロックが並び、最後に全結合層が続きます。

青の統計学は、東京大学を卒業後、事業会社でデータサイエンティストとして勤務する筆者が運営する、AI・データサイエンスの総合学習メディアです。 自身の大学時代の経験から、教科書だと分かりにくかった事項を克服でき、かつ実務で活かせる知識を楽しく学べるように、インタラクティブ学習ツール「DS Playground」を開発しており、大学での講義の材料としても利用されています。Xフォロワー1万人を突破!

