【SHAP】スタッキング(stacking)で特徴量の解釈はできるのか|pythonアンサンブル学習
こんにちは、青の統計学です。
機械学習アルゴリズムの精度向上において、アンサンブル学習は非常に重要な役割を果たしています。
アンサンブル学習とは、複数の学習アルゴリズムを組み合わせることで、予測精度を向上させる手法です。
本コンテンツでは、アンサンブル学習の一つであるスタッキング(stacking)に焦点を当て、その仕組みや実装方法を詳しく解説します。
また、複雑なモデルを使うことによる「特徴量の解釈」についても一定の示唆を与えられる内容となっております。
スタッキング(stacking)
スタッキングは、複数の基本モデル(base models)を組み合わせ、それらの予測結果を入力としてメタモデル(meta model)が新たな予測を行うアンサンブル学習手法です。スタッキングの仕組みは以下のようになります。
1:トレーニングデータをK分割し、K-1分割のデータで基本モデルを学習させます。
2:学習済みの基本モデルを使って、残り1分割のデータに対する予測を行います。
3:すべての分割について上記の手順を繰り返し、新たな特徴量として予測結果をまとめます。
4:新たな特徴量を用いてメタモデルを学習させ、最終的な予測を行います。
スタッキングと他のアンサンブル手法との違いは?
ブレンディング(blending)との違い
スタッキングとブレンディングの違いは、スタッキングが交差検証(cross-validation)を用いて基本モデルの予測結果を生成するのに対し、ブレンディングは固定の比率でデータを分割し、基本モデルの予測結果を生成します。
スタッキングは、結局いろんなモデルの線型結合として表すことができます。
$$f(x;a)={\sum_{k}a(β^k)}×f_{base}(x;β^k)$$
\(β^k\)はいろんなアルゴリズムkで推定されたパラメータを表しています。
バギング(bagging)との違いは?
バギングは、ブートストラップ法を機械学習に応用した手法です。
代表的なアルゴリズムは、ランダムフォレストです。
【ランダムフォレスト】ブートストラップ法を決定木に応用|python
データセットを復元抽出して、中間予測器という複数のモデルを作ります。
これは、ブートストラップ法という手法を取り入れています。
最終的には中間予測器の予測を集約して最終的な予測を得ます。
分類タスクの場合:各学習器の予測の多数決(最も多くの票を得たクラス)が最終的な予測となります。
回帰タスクの場合:各学習器の予測の平均が最終的な予測となります。
バギングは、オーバーフィッティングを抑制し、モデルの分散を低減することができるため、単一の学習器よりも堅牢な予測が可能になります。
また、複数の学習器が独立に訓練されるため、計算処理を並列化できる利点もあります
ブースティング(boosting)との違いは?
ブースティングは、学習済みのモデルの誤りに重点を置いて次のモデルを学習し、最終的に加重平均や多数決を用いて予測を行います。
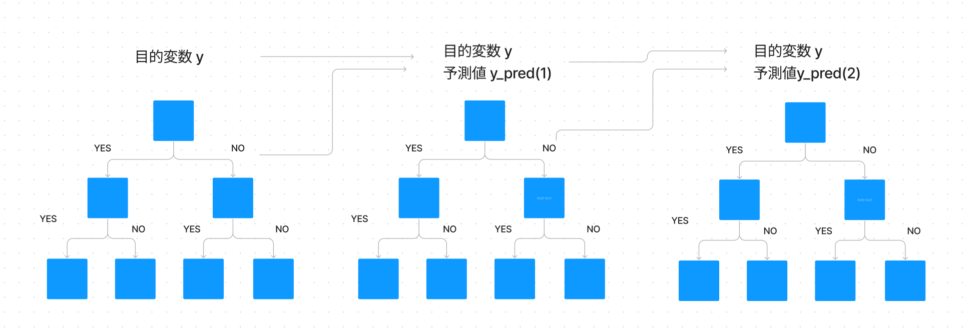
スタッキングは、前述の通り、異なるモデルの予測を組み合わせることで性能を向上させる手法です。
【XGB】交差検証法を使った勾配ブースティング決定木の実装|python
【XGB】GridSearchを使いつつ特徴量重要度を知りたいッ‥!|python
スタッキングにおいては、基本モデルとメタモデルとしてさまざまな機械学習アルゴリズムが利用されます。
以下は、スタッキングでよく用いられるアルゴリズムです。
・ランダムフォレスト(Random Forest)
・勾配ブースティング(Gradient Boosting)
・XGBoost
・LightGBM
・CatBoost
これらのアルゴリズムは、高い性能を持ちながら、異なる特性やハイパーパラメータを持つため、スタッキングにおいて有効な組み合わせが見つかりやすいです。
例えば、以下の「人の寿命は予測できるのか」という論文では、ランダムフォレストとラッソ回帰、勾配ブースティング決定木アルゴリズムのスタッキングが使われています。予測の精度は悪かったみたいですが…
Predictive modeling of US healthcare spending in late life(Einav 2018)
CODE|python
以下のコンテンツで説明した通り、一般的には「汎化性能」と「解釈のしやすさ」はトレードオフです。
【SHAP】特徴量重要度や寄与度、限界効果を意思決定者にうまく伝えたい話|python
つまり、予測精度を追求しようとしてモデルを複雑にすればするほど、「結局どの特徴量が重要なんだっけ??」と、精度の高いモデルを前に当惑してしまうでしょう。
今回は、スタッキングを使いつつ、予測結果を解釈できるようにSHAPという手法を使います。
流れとしては、
①交差項を使って特徴量を増やす
②特徴量重要度が低い特徴量はカットする
③スタッキングを使って予測を行う
④SHAPを使って、重要な特徴量を見る
となります。
import itertools
import numpy as np
import pandas as pd
import shap
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.ensemble import StackingClassifier
from sklearn.preprocessing import PolynomialFeatures
# データのロード
data = load_breast_cancer()
X, y = data.data, data.target
feature_names = data.feature_names
#シード値の設定
seed=42
#交差項の作成
#2次元まで
poly = PolynomialFeatures(degree=2, interaction_only=True, include_bias=False)
X_poly = poly.fit_transform(X)
feature_names_poly = poly.get_feature_names(input_features=feature_names)
#特徴量選択
#分散分析
selector = SelectKBest(f_classif, k=30)
X_selected = selector.fit_transform(X_poly, y)
selected_feature_indices = selector.get_support(indices=True)
selected_feature_names = [feature_names_poly[i] for i in selected_feature_indices]
#教師データと評価データの分割
X_train, X_test, y_train, y_test = train_test_split(X_selected, y, test_size=0.2, random_state=seed)
#基本モデルとメタモデルの設定
base_models = [
('rf', RandomForestClassifier(random_state=seed)),
('gb', GradientBoostingClassifier(random_state=seed))
]
meta_model = LogisticRegression(random_state=42)
#ハイパーパラメータのチューニング
#グリッドサーチ
param_grid_rf = {
'min_samples_leaf': [3, 5, 7],
'max_depth': [5, 8, 10]
}
param_grid_gb = {
'max_depth': [3, 5, 8],
'learning_rate': [0.01, 0.1, 0.2]
}
grid_search_rf = GridSearchCV(base_models[0][1], param_grid_rf, scoring='roc_auc', cv=5)
grid_search_gb = GridSearchCV(base_models[1][1], param_grid_gb, scoring='roc_auc', cv=5)
grid_search_rf.fit(X_train, y_train)
grid_search_gb.fit(X_train, y_train)乳がんデータをロードします。
今回は、2次元まで交差項を作って特徴量の選択を行います。
SelectKBestは、特徴量選択の方法の1つで、単変量統計テストに基づいて、特徴量をスコアリングし、上位k個の特徴量を選択します。
この例では、f_classifというANOVA(分散分析)F値を用いたテストが使われています。
f_classifは、各特徴量が目的変数(クラスラベル)とどの程度関連しているかを評価します。
【交絡を解決!?】共分散分析(ANCOVA)とは一体何なのか。
具体的には、F値は以下の式で計算されます。
$$F = \frac{MS_{between}}{MS_{within}}$$
ここで、MS_betweenは群間の平均平方(Mean Square Between)、MS_withinは郡内の平均平方(Mean Square Within)です。
SelectKBestは、各特徴量のF値を計算し、上位k個の特徴量を選択します。
より洗練された特徴量選択の方法として、再帰的特徴消去(Recursive Feature Elimination, RFE)があります。
RFEは、機械学習アルゴリズムによるモデルの精度に基づいて特徴量を選択するため、より現実的な特徴量選択が可能です。
スタッキングにおけるメタモデルと基本モデル
スタッキングでは、基本モデルと呼ばれる複数の学習アルゴリズムを組み合わせて、それらの予測をメタモデルと呼ばれる別の学習アルゴリズムに入力します。
メタモデルは、基本モデルの予測を組み合わせて最終的な予測を生成する役割を果たします。
基本的に、基本モデルは個々の学習アルゴリズムであり、メタモデルはそれらの予測を統合するための学習アルゴリズムです。
スタッキングには、過学習のリスクやハイパーパラメータの調整が難しいという課題があります。
過学習を防ぐためには、交差検証(cross-validation)の分割数を適切に設定することや、モデルの複雑さを制御するための正則化(regularization)を適用することが重要です。
また、ハイパーパラメータの調整にはグリッドサーチ(GridSearchCV)やランダムサーチ(RandomizedSearchCV)などの手法を用いることができます。
今回はグリッドサーチを使っています。
他にも、ベイズ最適という手法もあります。
【kaggle】ベイズ最適化とXGBでtitanicの予測問題を解く|python
残念ながら、StackingClassifierをSHAP Explainerに直接渡すことができません。
SHAP Explainerは、通常、個々のモデルに対して使用されます。
StackingClassifierは複数のモデルを含んでいるため、互換性がありません。
この問題を解決するために、StackingClassifierの各基本モデルに対してSHAP値を個別に計算し、それらを組み合わせることができます。
今回は、交差項やスタッキングで複雑になったモデルに対し、特徴量がどうきくのか解釈を試みるコンテンツです。
#基本モデルごとに特徴量重要度を算出
rf_feature_importances = grid_search_rf.best_estimator_.feature_importances_
gb_feature_importances = grid_search_gb.best_estimator_.feature_importances_
#特徴量重要度を正規化
rf_feature_importances = rf_feature_importances / np.sum(rf_feature_importances)
gb_feature_importances = gb_feature_importances / np.sum(gb_feature_importances)
#教師データから予測を行う
rf_test_predictions = grid_search_rf.best_estimator_.predict_proba(X_test)[:, 1]
gb_test_predictions = grid_search_gb.best_estimator_.predict_proba(X_test)[:, 1]
#各基本モデルの予測と、教師データの相関
rf_corr = np.corrcoef(rf_test_predictions, y_test)[0, 1]
gb_corr = np.corrcoef(gb_test_predictions, y_test)[0, 1]
#基本モデルの重みを計算
rf_weight = rf_corr / (rf_corr + gb_corr)
gb_weight = gb_corr / (rf_corr + gb_corr)
#勾配ブースティング(XGBoost, LightGBM, CatBoostなど)で作成したモデルを読み込み、Shap値を導くためのインスタンス
rf_explainer = shap.TreeExplainer(grid_search_rf.best_estimator_)
gb_explainer = shap.TreeExplainer(grid_search_gb.best_estimator_)
#各基本モデルのShap値を計算
rf_shap_values = np.array(rf_explainer.shap_values(X_test))[1]
gb_shap_values = np.array(gb_explainer.shap_values(X_test))[1]
#重みをつけたShap値を計算
stacking_shap_values = rf_weight * rf_shap_values + gb_weight * gb_shap_values
#絶対値をとり、平均化
stacking_feature_importances_shap = np.mean(np.abs(stacking_shap_values), axis=0)
#特徴量重要度を降順にする
sorted_indices = np.argsort(stacking_feature_importances_shap)[::-1]
sorted_feature_names = [selected_feature_names[i] for i in sorted_indices]
sorted_feature_importances_shap = stacking_feature_importances_shap[sorted_indices]
#視覚化
plt.figure(figsize=(12, 6))
plt.bar(selected_feature_names, sorted_feature_importances_shap)
plt.xticks(rotation=90)
plt.xlabel("Features")
plt.ylabel("SHAP Importance")
plt.title("SHAP-based feature importances for the stacking model")
plt.show()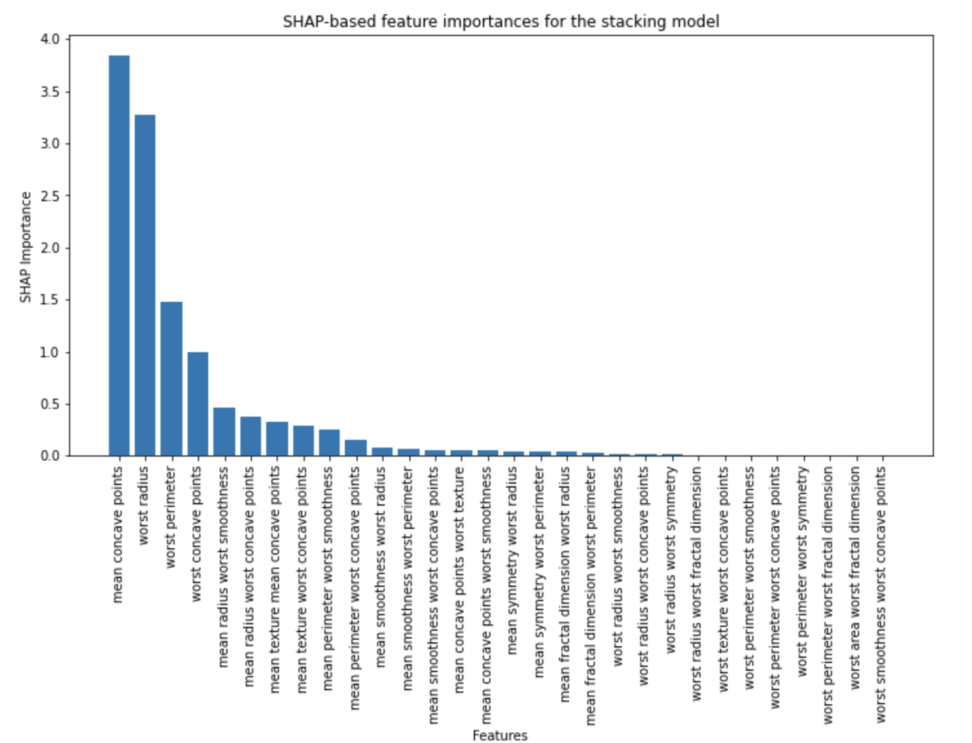
このコードでは、Random ForestとGradient Boostingの2つの基本モデルのSHAP値を、重みに従って組み合わせています。
ただし、このアプローチはあくまで推定であり、完全に正確ではないことに注意してください。
まとめ
スタッキングは、異なる機械学習アルゴリズムを組み合わせることで予測精度を向上させるアンサンブル手法です。
バギングやブースティングとは異なる特性を持ち、多様なモデルを組み合わせることで効果を発揮します。
ただし、過学習のリスクやモデルの複雑さが増すことから、モデル選択やハイパーパラメータ調整が重要な要素となります。

青の統計学は、東京大学を卒業後、事業会社でデータサイエンティストとして勤務する筆者が運営する、AI・データサイエンスの総合学習メディアです。 自身の大学時代の経験から、教科書だと分かりにくかった事項を克服でき、かつ実務で活かせる知識を楽しく学べるように、インタラクティブ学習ツール「DS Playground」を開発しており、大学での講義の材料としても利用されています。Xフォロワー1万人を突破!

