【XGB】GridSearchを使いつつ特徴量重要度を知りたいッ‥!|python
決定木系のアルゴリズムには、feature_importanceというメソッドがあります。
ただ、GridSearchなどのハイパーパラメーターチューニングと一緒に行うと、
「GridSearchCVには、feature_importanceというメソッドがありません。」などとエラーが発生することがしばしばあります。
今回は、GridSearchを行いつつ、特徴量の重要度まで出力できるコードをご紹介いたします。
勾配ブースティング決定木アルゴリズム
GBDT(gradient boosting decision tree)とは、アンサンブル手法のブースティングの一種です。
逐次的に予測木を構築するということに特徴があり、過去の予測木の適合度を活用します。
バギングとは異なり、初期のモデルはとてもシンプルです。
\(\hat{f(x)}=0\)を初期のモデルとし、パラメータは\({B,λ,d}\)で左からブースティング回数\(b=1…\)、学習率、木の深さです。
①Xから予測誤差を計算する
$$\hat{f(x)}←\hat{f(x)}+λ\hat{f(x)}^{b}$$
②残差を更新していく
$$r_{i}←r_{i}-λ\hat{f^{b}(x)}$$
右辺の第2項を減じることで、予測できなかったものが少しずつ減っていくと言うアルゴリズムです。
bが大きすぎると過学習してしまうし、dが大きすぎると計算が遅いし過学習してしまいます。
また、λが小さいといつまで経っても学習が終了しません。
\(\hat{f(x)}=\sum_{b}^{B}λ\hat{f^{b}(x)}\)のような推定モデルができます。
過学習の話で余談ですが、パラメータが増えるとテスト誤差は大きくなるというのが一般的だったのが、Transformerを使ったLLMにはスケール則という、データやパラメータ、計算資源を増やせばテスト誤差が下がるという話があり、この辺りの原理がまだまだわかっていません。
→我々の脳の神経細胞も2000億くらいニューロンがあり、1個のニューロンも1万個くらいのシナプスによって構成されており、モデルで例えるととても大きいです。LLMは我々の知能に近づいてきたということでしょうか、非常に興味深いです。
ボストン住宅価格のデータセット(boston housing price dataset)
今回は、scikitlearnでロードできるモジュール「ボストン住宅価格のデータセット」を使います。
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import xgboost as xgb
boston = load_boston()
# Pandasによるデータの表示
df_target = pd.DataFrame(boston["target"], columns=["target"])
df_data = pd.DataFrame(boston["data"], columns=boston["feature_names"])
df = pd.concat([df_target, df_data], axis=1)
df.head()| target | CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | |
| 0 | 24.0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 |
| 1 | 21.6 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 |
| 2 | 34.7 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 |
| 3 | 33.4 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 |
| 4 | 36.2 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 |
5行だけ出力してみました。
それぞれの特徴量は以下のような内容となっています。
Data Set Characteristics: :Attribute Information (in order): - CRIM per capita crime rate by town :犯罪発生率 - ZN proportion of residential land zoned for lots over 25,000 sq.ft. :25000平方フィート以上の住宅区間の割合 - INDUS proportion of non-retail business acres per town :非小売業の土地面積の割合 - CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise) :チャールズ側沿いかどうか(1:川沿い、0:川沿いではない) - NOX nitric oxides concentration (parts per 10 million) :窒素酸化物の濃度 - RM average number of rooms per dwelling :一戸あたりの平均部屋数 - AGE proportion of owner-occupied units built prior to 1940 :1940年よりも前に建てられた家屋の割合 - DIS weighted distances to five Boston employment centres :ボストンの主な雇用圏までの重み付き距離 - RAD index of accessibility to radial highways :幹線道路へのアクセス指数 - TAX full-value property-tax rate per $10,000 :10000ドルあたりの所得税率 - PTRATIO pupil-teacher ratio by town :教師あたりの生徒の数 - B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town :アフリカ系アメリカ人居住者の割合 - LSTAT % lower status of the population :低所得者の割合
常識的には、低所得者層の割合などがダイレクトに住宅価格と相関がありそうです。
あとは、所得とアフリカ系アメリカ人などの人種との交絡関係などが気になりどころです。
一旦、特徴量同士の相関係数を見るために相関行列を図示してみます。
corr_mat = df.corr(method='pearson')
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(50,40))
sns.heatmap(corr_mat,
vmin=-1.0,
vmax=1.0,
center=0,
annot=True, # True:格子の中に値を表示
fmt='.1f',
xticklabels=corr_mat.columns.values,
yticklabels=corr_mat.columns.values
)
plt.show()| target | CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | |
| target | 1.000000 | -0.388305 | 0.360445 | -0.483725 | 0.175260 | -0.427321 | 0.695360 | -0.376955 | 0.249929 | -0.381626 | -0.468536 | -0.507787 | 0.333461 | -0.737663 |
| CRIM | -0.388305 | 1.000000 | -0.200469 | 0.406583 | -0.055892 | 0.420972 | -0.219247 | 0.352734 | -0.379670 | 0.625505 | 0.582764 | 0.289946 | -0.385064 | 0.455621 |
| ZN | 0.360445 | -0.200469 | 1.000000 | -0.533828 | -0.042697 | -0.516604 | 0.311991 | -0.569537 | 0.664408 | -0.311948 | -0.314563 | -0.391679 | 0.175520 | -0.412995 |
| INDUS | -0.483725 | 0.406583 | -0.533828 | 1.000000 | 0.062938 | 0.763651 | -0.391676 | 0.644779 | -0.708027 | 0.595129 | 0.720760 | 0.383248 | -0.356977 | 0.603800 |
| CHAS | 0.175260 | -0.055892 | -0.042697 | 0.062938 | 1.000000 | 0.091203 | 0.091251 | 0.086518 | -0.099176 | -0.007368 | -0.035587 | -0.121515 | 0.048788 | -0.053929 |
| ‥ | ‥ | ‥ | ‥ | ‥ | ‥ | ‥ | ‥ | ‥ | ‥ | ‥ | ‥ | ‥ | ‥ | ‥ |
味気ないのでヒートマップにしてみます。
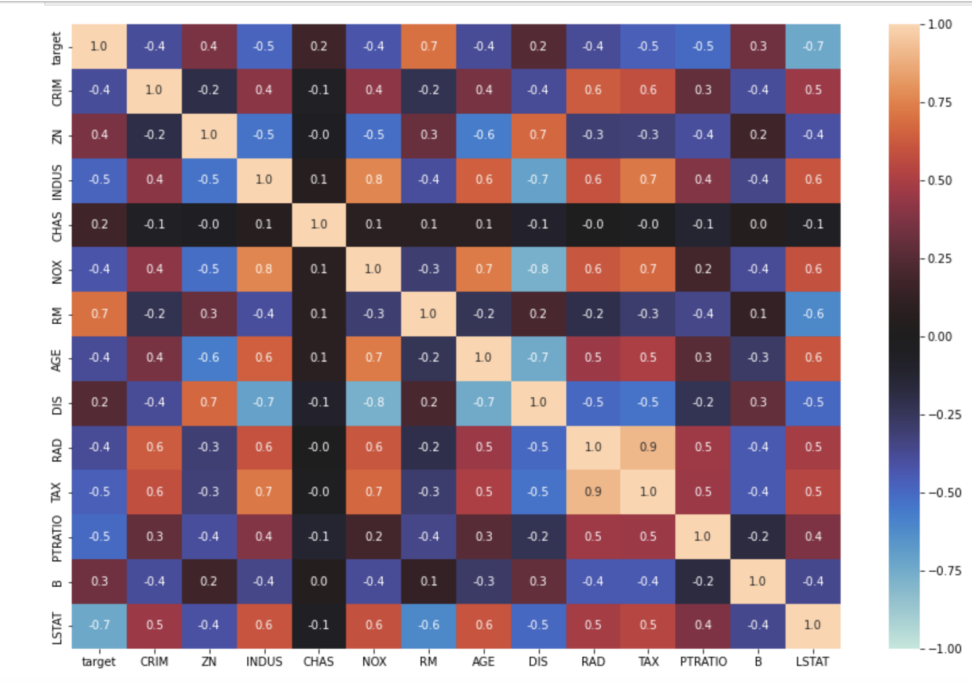
TAX-RAD(10000ドルあたりの所得税率、幹線道路へのアクセス指数)の相関が目立って高いことがわかります。
せっかく相関も見たし、多重共線性の問題があることも考え、TAXの特徴量だけ落とします。
多重共線性については、【説明変数の相関】多重共線性を解説します。をご覧くださいませ。
df = df.drop("TAX",axis=1)
y = df.loc[:,["target"]]
X = df.loc[:, "CRIM":]説明変数をXに、目的変数をyに代入します。
次にtrain_test_splitメソッドで教師データとテストデータに分けます。
# 訓練データとテストデータに分ける
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.5, random_state=0)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train = le.fit_transform(y_train)
y_valid = le.fit_transform(y_valid)
scores = {}
for max_depth in range(2, 10, 1):
for min_child_weight in range(1, 10, 1):
model = xgb.XGBClassifier(max_depth=max_depth,
min_child_weight=min_child_weight,
n_estimators=100,
random_state=42
)
model.fit(X_train, y_train)
scores[(max_depth, min_child_weight)] = model.score(X_valid, y_valid)
# 検証結果をscoresに格納
scores = pd.Series(scores)for文を使ってグリッドサーチを行います。
まず、scoresを辞書型で定義し、max_depthとmin_child_weightというキーに対し、スコアを紐づけて格納してあげます。
# 表示
print('ベストスコア:{:.2f}'.format(scores.max()))
print('その時のパラメータ(max_depth, min_child_weight):{}'.format(scores.idxmax()))
# ヒートマップを表示。縦軸にmax_depth、横軸にmin_child_weightを表示
sns.heatmap(scores.unstack())チューニングに少し時間がかかると思います。
各パラメータの値とその時のスコアがscoresに格納されており、優れたスコアを持つパラメータを取り出すといった考え方です。
2つしかパラメータをチューニングしていないので、2次のヒートマップで表してみます。
ベストスコア:0.02
その時のパラメータ(max_depth, min_child_weight):(2, 1)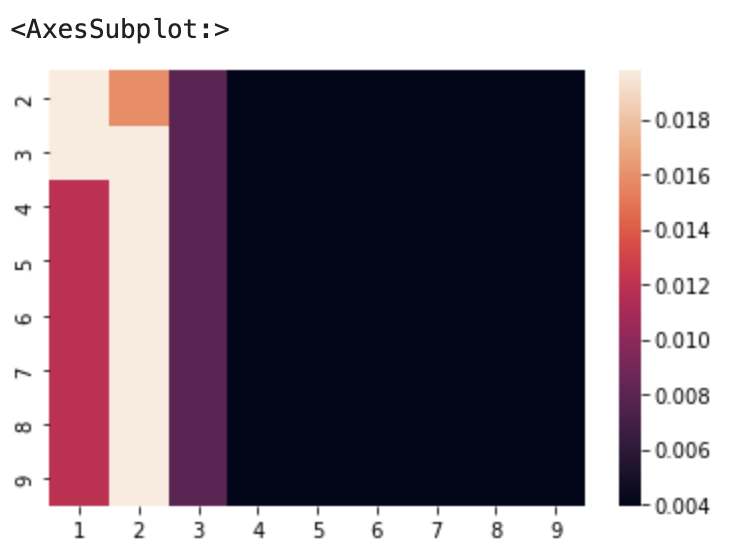
array_bst = np.array(scores.idxmax())
array_bst→array([2, 1])np.arrαyに変換させて、max_depthとmin_child_weightという変数に最適なパラメータを入れます。
max_depth = 2, min_child_weight = 1で良さそうです。
max_depth = array_bst[0]
min_child_weight = array_bst[1]
model_bst = xgb.XGBClassifier(max_depth=max_depth,
min_child_weight=min_child_weight,
n_estimators=100,
random_state=42
)
model_bst.fit(X_train, y_train, eval_metric='rmse')
# 過学習確認
pred_xgb_class = model_bst.predict(X_valid)
pred_xgb_proba = model_bst.predict_proba(X_valid)[:, 1]
# 過学習確認
print("教師データ",model_bst.score(X_train, y_train))
print("テストスコア",model_bst.score(X_valid, y_valid))教師データ 0.8656126482213439
テストスコア 0.019762845849802372出力結果です。ちょっと過学習気味ですかね‥。
特徴量のエンジニアリングやチューニングなどの検討はもっと必要そうです。
feature = pd.DataFrame()
feature["columns"] = X.columns
feature["score"] = model_bst.feature_importances_
feature = feature.sort_values(by='score', ascending=False)
plt.figure(figsize=(10,6))
plt.plot(feature["columns"], feature["score"])
plt.title("feature_importance")
plt.show()最後に特徴量の重要度をグラフで表します。
ascending = Falseとすると降順で特徴量を並べることができます。
feature_importances_というメソッドを使えば、特徴量重要度をリスト形式で渡してくれます。
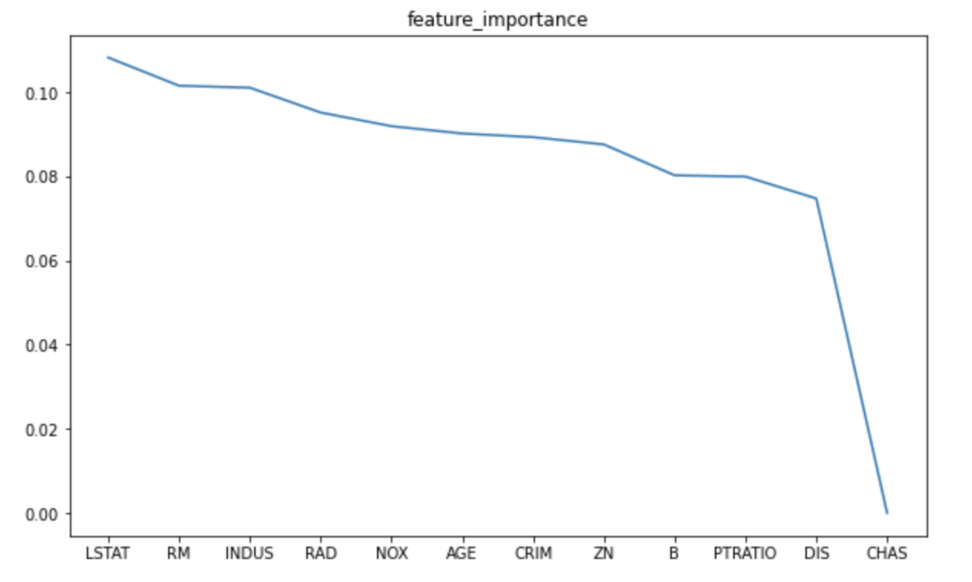
LSTATがもっとも重要だそうです。低所得者の割合です。
当然と言えば当然ですが、「低所得者層が多いから住宅価格が安い」などの因果関係は全く説明できていないのでご注意ください。
他は、RM:1戸あたりの平均部屋数やINDUS:非小売業の土地面積の割合です。
CHASはチャールズ川に近いかどうかですが、ほとんど住宅価格とは関係なさそうです。
雨が多く水害が頻繁にある地域だと、川の近くかどうかという特徴量は住宅価格に影響を及ぼしそうですね。
注意点として、この特徴量重要度はノードの分岐の際に該当の特徴量を使うと情報利得が高いというだけであり、
この特徴量が一単位増加した時に、被説明変数の増加(または減少)が大きいとは言い切れない(つまり限界効果の話はしていない)ので注意しましょう。
もっと深く見るには部分依存の分析などが必要です。
統計検定のチートシートは以下をクリック!
【最短合格】統計検定準一級のチートシート|難易度や出題範囲について
【最短】統計検定2級合格ロードマップとチートシート|おすすめの本について
他の機械学習コンテンツについては以下をご覧ください。
【Sequential】Kerasを使ったニューラルネットワーク|python
【XGB】交差検証法を使った勾配ブースティング決定木の実装|python
【ランダムフォレスト】ブートストラップ法を決定木に応用|python
【判別問題】サポートベクトルマシン(SVM)の仕組み|python

