混合ガウス分布とは?わかりやすく解説
はじめに
正規分布(ガウス分布)は、統計学や機械学習における基本的な確率分布であり、データが平均を中心に左右対称に分布する特徴を持ちます。この分布を拡張したもの混合ガウス分布(Gaussian Mixture Model, GMM)です。
GMMは、複数のガウス分布を組み合わせることで、より複雑なデータ構造をモデル化することが可能です。本記事では、混合ガウス分布を解説します。
とはいいつつ、個人的には、多変量正規分布とかの方が理解が難しい気がしております。
正規分布について理解したい方は、こちらの記事がおすすめです。


1. ガウス分布の基本概念
1.1 ガウス分布とは
まず、ガウス分布をおさらいしましょう。
確率密度関数(PDF)が次の式で表される確率分布のことですね。
$${f(x|\mu,\sigma^2)=\frac{1}{\sqrt{2\pi \sigma^2}}exp(-\frac{(x-\mu)^2}{2\sigma^2})}$$
- ${\mu}$(平均値):分布の中心を決める。
- ${\sigma^2}$(分散):データのばらつきを示す。
- 標準偏差 ${\sigma}$は分散の平方根。
ガウス分布は、中心極限定理により、様々な自然現象や社会現象に頻繁に現れることが知られています。
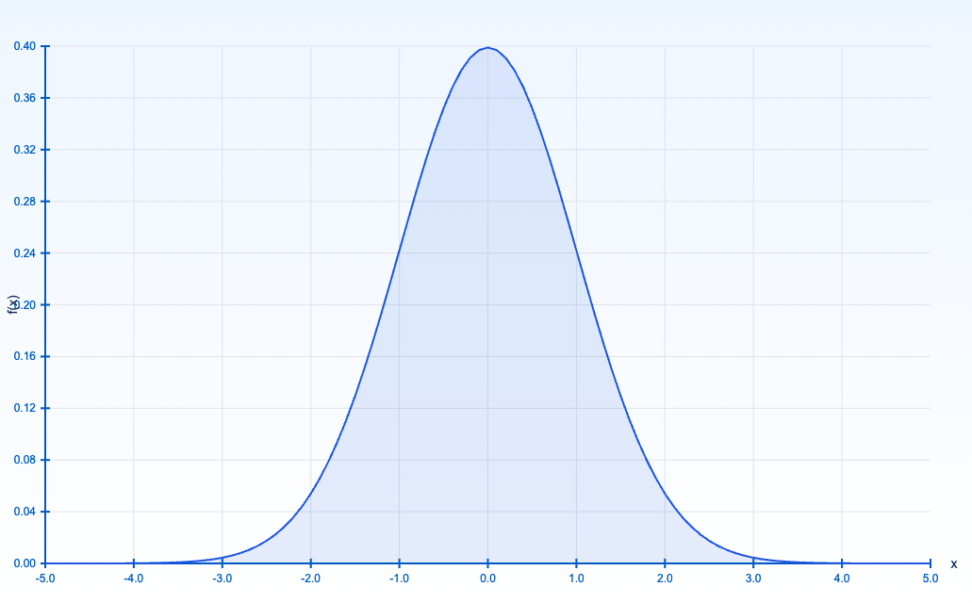
データが平均値を中心に左右対称に分布する特性を持ちますので、上のような、左右対称の釣鐘型の確率密度関数になります。
ただ、正規分布にも限界はあります。

例えば、テストの点数分布を考えた場合、あるクラスの生徒全員がほぼ同じ学力水準にあるなら、1つのガウス分布で十分かもしれません。しかし、実際には「優秀層」と「平均層」のように異なる2つの集団が混在している場合、一つのガウス分布では適切にモデリングできませんね。
2. 混合ガウス分布の定義と数学的表現
2.1 混合ガウス分布の数式表現
混合ガウス分布は、複数のガウス分布を線形結合した形で表されます。
つまり、各ガウス分布は異なる平均値と共分散を持ち、これらの分布の重み付き和として全体の分布が表現されます。
$${p(\mathbf{x}) = \sum_{k=1}^K \pi_k \mathcal{N}(\mathbf{x} | \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)}$$
- ${K}$:ガウス分布の数(クラスターの数)
- ${\pi_k}$(混合比):各ガウス分布の寄与割合(${\sum \pi_{k = 1}}$)
- ${\mathcal{N}(x | \mu_k, \Sigma_k)}$:平均 ${\mu_k}$ と共分散行列 ${\Sigma_k}$を持つ正規分布
このモデルは、データが複数の異なるガウス分布に由来していると仮定することで、単純なガウス分布では捉えきれない複雑な分布を表現できます。
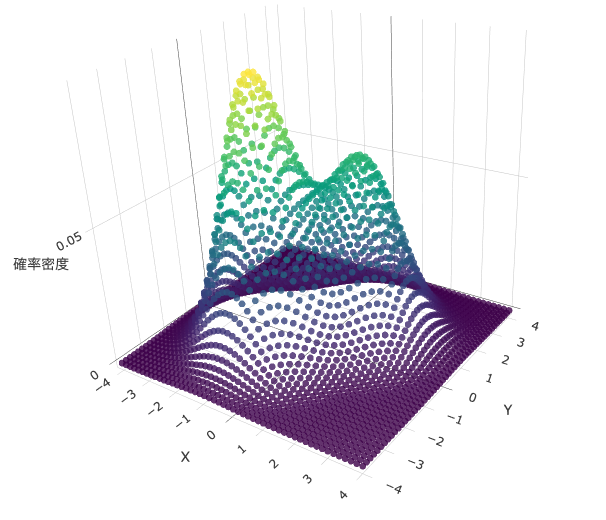
パラメータによっては、上のように山の頂点が二つあるような確率密度関数を可視化させることができます。
混合ガウス分布は、特に教師なし学習のクラスタリング手法としても広く用いられ、特にEMアルゴリズム(Expectation-Maximization Algorithm)を用いたパラメータ推定が特徴的(後述します!)です。
混合ガウスの嬉しいポイント
ガウス分布は単一の平均と分散でデータを表現しますが、混合ガウス分布は複数のガウス分布を用いることで、より複雑なデータの分布を表現します。これにより、データが複数の異なるクラスターに分かれている場合でも、全体の分布を効果的にモデル化することが可能です。
2.2混合ガウス分布の期待値と分散
ここでは期待値と分散を見てみましょう。
期待値
混合ガウス分布の期待値は、各ガウス分布の期待値を混合係数で重み付けして足し合わせることで求められます。
$${ \mathbf{E}[x] = \sum_{k=1}^K \pi_k \mu_k }$$
- ${K}$: ガウス分布の個数
- ${\pi_k}$: ${k}$ 番目のガウス分布の混合係数 (${0 \le \pi_k \le 1}$, ${\sum_{k=1}^K \pi_k = 1}$)
- ${\mu_k}$: ${k}$ 番目のガウス分布の平均
線形性(期待値の和は和の期待値)を利用して、各ガウス分布の期待値の重み付き和として表現します
分散
$${\mathbf{V}[x] = \sum_{k=1}^K \pi_k \left( \Sigma_k + (\mu_k – \mathbb{E}[x])(\mu_k – \mathbb{E}[x])^T \right) }$$
- ${\Sigma_k}$: ${k}$ 番目のガウス分布の共分散行列
各ガウス分布の分散と、平均とのずれの二乗の期待値の重み付き和として表現します
具体例
2つのガウス分布からなる混合ガウス分布を考えます。
- ${\pi_1 = 0.6, \mu_1 = 0, \Sigma_1 = 1}$
- ${\pi_2 = 0.4, \mu_2 = 5, \Sigma_2 = 2}$
期待値と分散は以下のように計算できます。
- 期待値
- ${\mathbb{E}[x] = 0.6 \times 0 + 0.4 \times 5 = 2 }$
- 分散
- ${ \mathbb{V}[x] = 0.6 \times (1 + (0 – 2)^2) + 0.4 \times (2 + (5 – 2)^2) = 11.8}$
結構わかりやすいと思います。
3.パラメータ推定:EMアルゴリズム
混合ガウス分布のパラメータ (${\pi_k, \mu_k, \Sigma_k}$) を推定するために、EMアルゴリズムが用いられます。EMアルゴリズムは、観測されない潜在変数(この場合は、各データ点がどのガウス分布に属するか)が存在する場合に、尤度を最大化するための手法です。


3.1 EMアルゴリズムの概要
EMアルゴリズムは、観測されない潜在変数を考慮しながら尤度を最大化する方法です。
具体的には、混合ガウス分布の対数尤度関数を最大化することで、各パラメータの最尤推定値を求める
手順
- Eステップ (Expectation step)
- 現在のパラメータの値を用いて、各データ点が各ガウス分布に属する確率(責任度)を計算します。
- Mステップ (Maximization step)
- Eステップで計算した責任度を用いて、各パラメータを更新します。
3.2 EMアルゴリズムの詳細な手順
- 初期化: 各パラメータ ${\pi_k, \mu_k, \Sigma_k}$ に適切な初期値を設定します。
- 例えば、${\pi_k}$はランダムに、${\mu_k}$ はデータ点からランダムに選び、${\Sigma_k}$は単位行列に設定するなどが考えられます。
- Eステップ: 各データ点 ${x_i}$と各ガウス分布 ${k}$ に対して、責任度 ${r_{ik}}$ を以下の式で計算します。
$${r_{ik} = \frac{\pi_k \mathcal{N}(x_i | \mu_k, \Sigma_k)}{\sum_{j=1}^{K} \pi_j \mathcal{N}(x_i | \mu_j, \Sigma_j)} }$$
${\mathcal{N}(x_i | \mu_k, \Sigma_k)}$は、データ点 ${x_i}$ がガウス分布 ${k}$ に従う確率密度関数を表します。
- Mステップ: Eステップで計算した責任度 ${r_{ik}}$を用いて、各パラメータを以下の式で更新します。
- 混合係数: ${\pi_k^{new} = \frac{1}{N} \sum_{i=1}^{N} r_{ik} }$
- ${N}$ はデータ点の総数です。
- 平均ベクトル: ${\mu_k^{new} = \frac{\sum_{i=1}^{N} r_{ik} x_i}{\sum_{i=1}^{N} r_{ik}} }$
- 共分散行列: ${ \Sigma_k^{new} = \frac{\sum_{i=1}^{N} r_{ik} (x_i – \mu_k^{new})(x_i – \mu_k^{new})^T}{\sum_{i=1}^{N} r_{ik}} }$
- 混合係数: ${\pi_k^{new} = \frac{1}{N} \sum_{i=1}^{N} r_{ik} }$
- 収束判定: 対数尤度が十分に変化しなくなるまで、EステップとMステップを繰り返します。
- 対数尤度は、以下の式で計算
$${ \mathcal{L} = \sum_{i=1}^{N} \log \left( \sum_{k=1}^{K} \pi_k \mathcal{N}(x_i | \mu_k, \Sigma_k) \right) }$$
Eステップでは、現在のパラメータを用いて潜在変数の期待値を計算し、Mステップでは、その期待値を用いてパラメータを更新します。このプロセスを収束するまで繰り返すことで、最適なパラメータが得られます
まとめ
- 混合ガウス分布は、数学的には各ガウス分布の加重平均として表現されます。各ガウス分布の確率密度関数にその分布の重みを掛け合わせたものの和として表される。
- 混合ガウス分布のパラメータ推定方法の中心には、EMアルゴリズム(期待値最大化法)が位置しており、EステップとMステップを交互に繰り返すことで、パラメータを最適化する。

青の統計学は、東京大学を卒業後、事業会社でデータサイエンティストとして勤務する筆者が運営する、AI・データサイエンスの総合学習メディアです。 自身の大学時代の経験から、教科書だと分かりにくかった事項を克服でき、かつ実務で活かせる知識を楽しく学べるように、インタラクティブ学習ツール「DS Playground」を開発しており、大学での講義の材料としても利用されています。Xフォロワー1万人を突破!

