共分散分析(ANCOVA)とは?回帰分析や分散分析との違いもわかりやすく解説
こんにちは、青の統計学です。
今回は、共分散分析について解説いたします。交絡因子等のバイアスを排除する上での便利な手法ですので、これを機にしっかり理解しましょう。

今回は、質的なデータと量的なデータという切り口でデータを見ます。
共分散分析の数学的背景
共分散分析を理解する上で、まずその元とも言える二つの統計手法、分散分析(ANOVA: Analysis of Variance)と回帰分析(Regression Analysis)について触れておく必要があります。共分散分析は、これら二つの手法の特性を組み合わせたハイブリッドなモデル、つまり一般線形モデルの一種として位置づけられます。


分散分析と回帰分析について
分散分析は、通常、カテゴリカルな説明変数(例:治療法A、治療法B、プラセボといったグループ)が、連続的な目的変数(例:血圧、テストの点数)に与える影響を比較する際に用いられます。例えば、「異なる3つの学習方法が、学生のテストの点数に差をもたらすか?」といった問いに答えることができます。
水準間平方和や、因子〜のようにパターン別にアウトプットを比較してF統計量を出していましたね。
一方、回帰分析は、連続的な説明変数(例:勉強時間、年齢)が、連続的な目的変数に与える影響をモデル化する際に用いられます。例えば、「勉強時間が長くなるほど、テストの点数は上がるか?」といった関係性を直線(線形回帰)などで表現します。
一方、共分散分析は、カテゴリカルな説明変数(要因)の効果を評価したいが、同時に連続的な「共変量(Covariate)」と呼ばれる変数の影響も考慮に入れたい場合に用いられるのです。
そもそも共変量とは
共変量とは、目的変数に影響を与える可能性のある、しかし主要な関心事ではない連続的な変数のことです。例えば、先ほどの学習方法の例で言えば、学生の「元々の学力」が共変量に当たります。学習方法の効果を純粋に評価するためには、この元々の学力の影響を「調整」する必要があるわけです。
共分散分析のモデル式
共分散分析の基本的なモデルは、以下のように表現できます。
$${Y_{ij} = \mu + \alpha_i + \beta(X_{ij} – \bar{X}_{..}) + \epsilon_{ij}}$$
- $Y_{ij}$: $i$番目のグループの$j$番目の観測値(目的変数)
- $\mu$: 全体の平均
- $\alpha_i$: $i$番目のグループの効果(主要な関心事)
- $\beta$: 共変量$X$の回帰係数(傾き)
- $X_{ij}$: $i$番目のグループの$j$番目の観測値における共変量の値
- $\bar{X}_{..}$: 共変量$X$の全体の平均
- $\epsilon_{ij}$: 誤差項(正規分布に従うと仮定される)
この式を見ると、分散分析のモデル($Y_{ij} = \mu + \alpha_i + \epsilon_{ij}$)に、共変量$X$による線形項$\beta(X_{ij} – \bar{X}_{..})$が追加されていることがわかります。
共変量$X$を全体の平均$\bar{X}_{..}$で中心化しているのは、モデルの解釈を容易にするためです。これにより、グループ効果$\alpha_i$は、共変量$X$が全体の平均値である場合のグループ間の差として解釈できるようになります。
ここまでの内容を国語的に整理すると、ANCOVAは因子と共変量(covariate)が目的変数に及ぼす影響を同時に考慮しながら、独立変数間の平均値の違いを検定する統計手法です。共変量を考慮することで、誤差のばらつきを減らし、独立変数間の効果の検出力を向上させることができます。
調整済み平均(Adjusted Mean)の概念
共分散分析の最も重要な概念の一つが、調整済み平均(Adjusted Mean)です。これは、もしすべてのグループの共変量の値が同じ(例えば、共変量の全体の平均値)であったとしたら、目的変数の平均値はどのようになるか、という仮想的な平均値を示します。つまり、共変量の影響を統計的に「取り除いた」後の、純粋なグループ間の平均値の差を評価するために用いられます。
調整済み平均は、各グループの回帰直線上で、共変量の全体の平均値に対応する目的変数の値として算出されます。数式で表すと、グループ$i$の調整済み平均$\bar{Y}_{i(adj)}$は以下のようになります。
$${ \bar{Y}_{i(adj)} = \bar{Y}_i – \hat{\beta}(\bar{X}_i – \bar{X}_{..}) }$$
- $\bar{Y}_i$: $i$番目のグループの目的変数の観測平均
- $\hat{\beta}$: 共変量$X$の回帰係数の推定値
- $\bar{X}_i$: $i$番目のグループの共変量の観測平均
- $\bar{X}_{..}$: 共変量$X$の全体の平均
この式は、各グループの観測平均から、そのグループの共変量の平均が全体の共変量の平均からどれだけ離れているか($\bar{X}_i – \bar{X}_{..}$)に、共変量の効果($\hat{\beta}$)を掛けた分を「調整」していることを意味します。これにより、共変量の影響が均一化された状態でのグループ間の比較が可能となり、より正確な結論を導き出すことができるのです。


このように、共分散分析は、分散分析の枠組みの中で回帰分析の要素を取り入れることで、より精度の高い分析を可能にします。特に、実験や調査において、完全にランダム化することが難しい場合や、目的変数に影響を与える既知の連続的な要因が存在する場合に、使えると思います
とはいえ、共変量を調整すれば、何でもできるわけでもないです。そもそも、バイアスのほとんどは、実験の計画やデータの取り方で事前に除外しておく必要があります。しかし、今回の共分散分析を使えば、交絡因子を「データを取った後に」調整することができます。
具体例|分散分析や回帰分析との違いをもっと詳しく
分散分析(ANOVA)との違いと共変量調整の意義
共分散分析と最も比較されるのが、分散分析(ANOVA)です。両者ともに、カテゴリカルな要因が目的変数に与える影響を評価する点では共通しています。しかし、決定的な違いは、共分散分析が「共変量」の影響を統計的に調整する点にあります。
例えば、ある新しい学習方法の効果を検証する実験を考えましょう。学生をランダムに2つのグループ(新しい学習方法 vs. 従来の学習方法)に分け、一定期間後にテストを実施します。もし、このグループ分けが完全にランダムに行われ、両グループの学生の「元々の学力」に差がなければ、分散分析で十分そうですね
しかし、現実には、完全に均質なグループを作ることは難しい場合があります。もし、偶然にも新しい学習方法のグループに元々の学力が高い学生が多く集まってしまったらどうでしょう?この場合、テストの点数の差が、本当に学習方法の効果なのか、それとも元々の学力の差によるものなのかが分からなくなってしまいます。
ここで共分散分析が使えます。共分散分析は、この「元々の学力」(共変量)が目的変数(テストの点数)に与える影響を統計的に取り除き、その上で純粋な「学習方法」の効果を評価します。つまり、共変量の影響を調整することで、より正確にグループ間の比較を可能にします。
回帰分析との関係性:重回帰分析との類似点
重回帰分析は、複数の説明変数を用いて目的変数を予測する手法です。これらの説明変数には、連続変数だけでなく、ダミー変数(カテゴリカル変数を0と1で表現したもの)を用いることで、カテゴリカルな要因も組み込むことができます。
共分散分析は、カテゴリカルな要因をダミー変数として扱い、共変量とともに重回帰モデルに組み込んだものと解釈することができます。
$${ Y = \beta_0 + \beta_1 X + \beta_2 D_1 + \dots + \beta_k D_{k-1} + \epsilon }$$
- $Y$は目的変数
- $X$は共変量
- $D_1, \dots, D_{k-1}$はカテゴリカルな要因を表すダミー変数
この式は、共分散分析のモデル式と同じ構造を持っています。つまり、共分散分析は、重回帰分析の特殊なケースであり、特定の目的(共変量を調整した上でのグループ間の比較)に特化した形と考えることができます。
共分散分析の前提条件
OLSで解く回帰分析を元にする以上
- 共変量と目的変数の関係が線形である
- 誤差項$\epsilon_{ij}$は、平均0、分散$\sigma^2$の正規分布に従う
- 各観測値は互いに独立であること
などの、前提を元に使う必要があります。
結局どう使う?|デジタルマーケ領域
マーケ分野で考えてみます。
マーケ領域だと、様々な施策(例:広告キャンペーン、価格の変更、プロモーション)が顧客の行動(例:購買額、クリック率、コンバージョン率)に与える影響を分析します。この際、顧客の属性(例:年齢、所得、過去の購買履歴)が、施策の効果に影響を与える共変量となることがよくあります。
例えば、あるECサイトが新しいパーソナライズされた推薦ロジックを導入し、その効果を測定したいとします。顧客をランダムに新システム利用グループと従来システム利用グループに分け、一定期間後の購買額を比較します。

しかし、顧客の「過去の購買額」や「サイト滞在時間」といった要因が、新システムの導入前からすでに顧客の購買行動に影響を与えている可能性があります。これらの要因を共変量として共分散分析を行うことで、顧客の既存の行動パターンを調整した上で、純粋な推薦ロジックの効果を評価することができます。
共分散分析の数学的背景の深掘り
もう少し、数学的背景をふかぼってみます。
最小二乗法による推定
共分散分析における回帰係数の推定は、最小二乗法(Least Squares Method)に基づいて行われます。この手法は、観測値と予測値の差の二乗和を最小化することで、最適なパラメータを求める方法です。共分散分析のモデル式を再度確認すると
$${Y_{ij} = \mu + \alpha_i + \beta(X_{ij} – \bar{X}_{..}) + \epsilon_{ij}}$$
この式において、未知のパラメータ$\mu$、$\alpha_i$、$\beta$を推定するために、残差平方和(RSS: Residual Sum of Squares)を最小化します。
残差平方和は以下のように定義されます
$${RSS = \sum_{i=1}^{k} \sum_{j=1}^{n_i} (Y_{ij} – \hat{Y}_{ij})^2}$$
- $\hat{Y}_{ij}$は予測値
- $k$はグループ数
- $n_i$は$i$番目のグループのサンプルサイズ
最小二乗法の解は、偏微分を用いて求めることができます。
特に、共変量の回帰係数$\beta$の推定値$\hat{\beta}$は、以下の式で表されます
$${\hat{\beta} = \frac{\sum_{i=1}^{k} \sum_{j=1}^{n_i} (X_{ij} – \bar{X}_{..})(Y_{ij} – \bar{Y}_{i})}{\sum_{i=1}^{k} \sum_{j=1}^{n_i} (X_{ij} – \bar{X}_{..})^2}}$$
この式は、共変量と目的変数の共分散を、共変量の分散で割ったものに相当します。これを見ると、線形回帰における回帰係数の推定式と同じ構造を持っており、共分散分析が回帰分析の拡張であることがわかるかと思います。
分散の分解と平方和の構造
共分散分析の嬉しさの一つは、分散の分解です。これは、目的変数の総変動を、異なる要因による変動に分解することで、各要因の相対的な重要性を評価する手法です。
共分散分析における平方和の分解は、以下のように表現されます
$${SS_{Total} = SS_{Treatment} + SS_{Covariate} + SS_{Error}}$$
- $SS_{Total}$:総平方和(Total Sum of Squares)
- $SS_{Treatment}$:処理効果による平方和(Treatment Sum of Squares)
- $SS_{Covariate}$:共変量による平方和(Covariate Sum of Squares)
- $SS_{Error}$:誤差平方和(Error Sum of Squares)
そして、各平方和は以下のように計算されます
$${SS_{Total} = \sum_{i=1}^{k} \sum_{j=1}^{n_i} (Y_{ij} – \bar{Y}_{..})^2}$$
$${SS_{Covariate} = \hat{\beta}^2 \sum_{i=1}^{k} \sum_{j=1}^{n_i} (X_{ij} – \bar{X}_{..})^2}$$
$${SS_{Treatment} = \sum_{i=1}^{k} n_i (\bar{Y}_{i(adj)} – \bar{Y}_{..(adj)})^2}$$
$${SS_{Error} = SS_{Total} – SS_{Treatment} – SS_{Covariate}}$$
この分解により、共変量がどの程度目的変数の変動を説明しているか、そして処理効果がどの程度の変動を説明しているかを定量的に評価することができます。
F統計量と仮説検定の数学的構造
共分散分析における仮説検定は、F統計量を用いて行われます。主要な関心事である処理効果の有意性を検定する場合、以下の帰無仮説と対立仮説を設定します
– 帰無仮説($H_0$):$\alpha_1 = \alpha_2 = \cdots = \alpha_k = 0$(すべてのグループ効果が0)
– 対立仮説($H_1$):少なくとも一つの$\alpha_i \neq 0$
F統計量は、以下のように計算されます:
$${F = \frac{MS_{Treatment}}{MS_{Error}} = \frac{SS_{Treatment}/(k-1)}{SS_{Error}/(N-k-1)}}$$
- $MS$は平均平方(Mean Square)
- $N$は総サンプルサイズです。
この統計量は、帰無仮説が真である場合、自由度$(k-1, N-k-1)$のF分布に従います。
F統計量の分子は処理効果による変動の大きさを、分母は誤差による変動の大きさを表しています。もし処理効果が実際に存在するならば、分子は分母よりも大きくなり、F統計量は大きな値を取ります。逆に、処理効果が存在しない場合、F統計量は1に近い値を取ることになります。
共分散分析自体は出ないですが、この辺の統計量の大小比較は統計検定でも頻出ですね。

実装と因果推論的解釈
Pythonによる共分散分析の実装
共分散分析の理論的理解を深めるために、Pythonを用いた具体的な実装例を示します。ここでは、`scipy.stats`と`statsmodels`ライブラリを使用して、共分散分析を実行する方法を解説します。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import statsmodels.api as sm
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
# サンプルデータの生成
np.random.seed(42)
n_per_group = 30
groups = ['A', 'B', 'C']
# 共変量(例:事前テストの点数)
covariate = np.random.normal(50, 10, n_per_group * len(groups))
# グループ効果
group_effects = {'A': 0, 'B': 5, 'C': 10}
group_labels = np.repeat(groups, n_per_group)
# 目的変数(例:事後テストの点数)
outcome = []
for i, group in enumerate(group_labels):
# 共変量の効果(回帰係数 = 0.8)+ グループ効果 + ノイズ
y = 20 + 0.8 * covariate[i] + group_effects[group] + np.random.normal(0, 5)
outcome.append(y)
# データフレームの作成
df = pd.DataFrame({
'group': group_labels,
'covariate': covariate,
'outcome': outcome
})
# 共分散分析の実行
model = ols('outcome ~ C(group) + covariate', data=df).fit()
anova_table = anova_lm(model, typ=2)
print("ANCOVA結果:")
print(anova_table)
print("\n回帰係数:")
print(model.params)
print("\n調整済み平均の計算:")
# 調整済み平均の計算
covariate_mean = df['covariate'].mean()
adjusted_means = {}
for group in groups:
group_data = df[df['group'] == group]
observed_mean = group_data['outcome'].mean()
group_covariate_mean = group_data['covariate'].mean()
# 調整済み平均 = 観測平均 - β(グループ共変量平均 - 全体共変量平均)
adjusted_mean = observed_mean - model.params['covariate'] * (group_covariate_mean - covariate_mean)
adjusted_means[group] = adjusted_mean
print(f"グループ{group}: 観測平均={observed_mean:.2f}, 調整済み平均={adjusted_mean:.2f}")上では、3つのグループ(A、B、C)における教育介入の効果を、事前テストの点数を共変量として調整しながら評価しています。共分散分析により、各グループの真の効果を、事前の学力差を考慮した上で評価できます。
因果推論の観点からの解釈
共分散分析を因果推論の文脈で理解してみましょう。
他の記事でも解説しているので、知っていたら読み飛ばしてください。
1. 潜在的結果フレームワーク
因果推論において、各個体$i$は二つの潜在的結果を持つと考えます
- $Y_i(1)$:個体$i$が処理を受けた場合の結果
- $Y_i(0)$:個体$i$が処理を受けなかった場合の結果
個体レベルの因果効果は、$Y_i(1) – Y_i(0)$として定義されますが、実際には一つの個体について両方の結果を同時に観測することはできません(反実仮想)
処理群の平均的な潜在的結果$E[Y_i(1)]$と対照群の平均的な潜在的結果$E[Y_i(0)]$の差を推定することで、平均処理効果(Average Treatment Effect: ATE)を求めます
$${ATE = E[Y_i(1)] – E[Y_i(0)]}$$
このように共分散分析は、この問題を集団レベルで解決しようとするというわけですね。
2. 選択バイアスと共変量調整
現実の観察研究では、処理の割り当てがランダムでない場合があります。この場合、処理群と対照群の間に選択バイアス(Selection Bias)が生じる可能性があります。
選択バイアスは、以下のように表現できます
$${E[Y_i|T_i=1] – E[Y_i|T_i=0] = ATE + \text{Selection Bias}}$$
$T_i$は処理の割り当てを示すダミー変数です。
共分散分析は、観測可能な共変量$X_i$を調整することで、この選択バイアスを軽減しようとします。
条件付き独立性の仮定の下では
$${Y_i(1), Y_i(0) \perp T_i | X_i}$$
この仮定が満たされる場合、共変量を調整した処理効果の推定値は、真の因果効果に近づきます。
3. 共分散分析による因果効果の推定
共分散分析のモデル式を因果推論の観点から再解釈すると
$${Y_{ij} = \mu + \tau \cdot T_{ij} + \beta(X_{ij} – \bar{X}) + \epsilon_{ij}}$$
- $\tau$は処理効果(因果効果)
- $T_{ij}$は処理の割り当てを示すダミー変数
この式において、$\tau$の推定値$\hat{\tau}$は、共変量$X$を調整した上での平均処理効果の推定値となります。
万能のように思えますが、外的妥当性(共分散分析による因果効果の推定は、分析に用いられたサンプルに対してのみ妥当)という論点は残るので、異なる集団や状況における因果効果を推定する際には、追加的な仮定や検証が必要となります。
おまけ:傾向スコアマッチングと回帰不連続デザインとの関係について
ここからは、共分散分析以外で因果推論を行う手法を紹介いたします。
特定の説明変数の回帰係数の値に興味があるというリサーチクエスチョンの場合、因果推論という手法が使われます。
$$Y_{i} = τD_{i}+f(X)+u_{i}$$
上の回帰式で言うと、\(τ\)が知りたい因果効果です。
そもそも、全ての回帰係数を正確に求めることは社会科学の分野では現実的ではないです。
さて、因果推論の手法として、他にも傾向スコアマッチングや回帰不連続デザインなどの手法があります。
傾向スコアマッチングとは、各サンプルが割り付けを受ける確率が他の説明変数に対して独立になるように、属性が近いサンプル同士に似た値になるように「傾向スコア」と言う特徴量を加えます。
これによって、交絡因子によるバイアスを回避しようという目的があります。
一方、回帰不連続デザインとは、割り付けがある閾値を超えて行われる場合(例:テストの合格か不合格か)に使われる、閾値近傍のデータのみを使う回帰手法です。
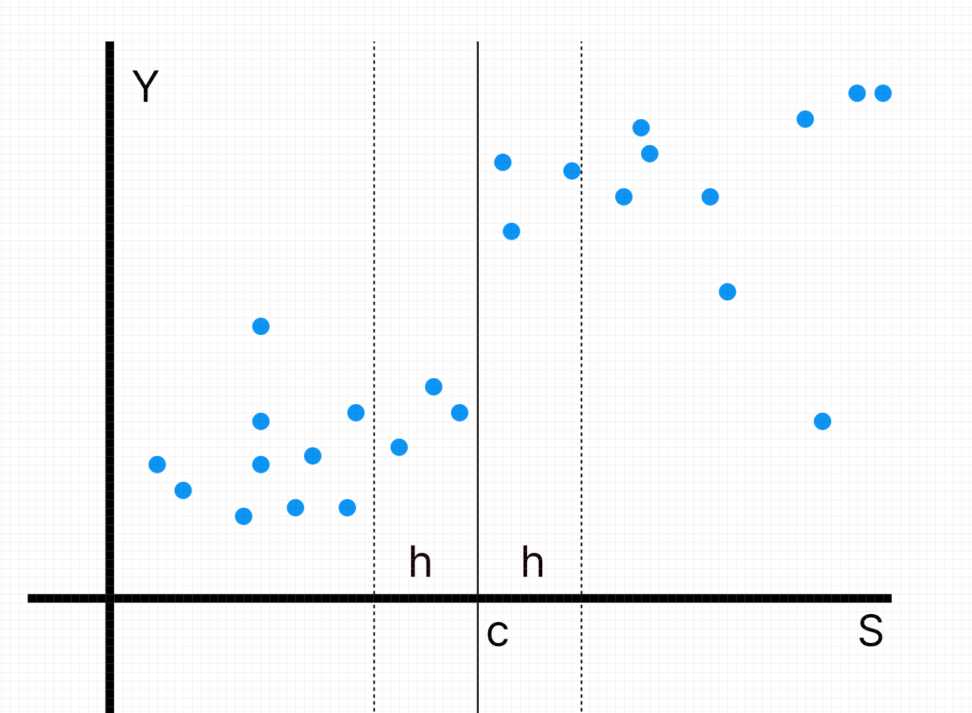
ギリギリ合格できなかった生徒と、合格最低点付近で合格できた生徒では、背景としての属性がほぼ同じであり、交絡因子の影響なしで割り付けが行われたと、解釈できると言うことです。
この辺りのトピックにも興味がある方は以下のコンテンツをご覧ください。



青の統計学は、東京大学を卒業後、事業会社でデータサイエンティストとして勤務する筆者が運営する、AI・データサイエンスの総合学習メディアです。 自身の大学時代の経験から、教科書だと分かりにくかった事項を克服でき、かつ実務で活かせる知識を楽しく学べるように、インタラクティブ学習ツール「DS Playground」を開発しており、大学での講義の材料としても利用されています。Xフォロワー1万人を突破!

