確率密度関数とは?確率質量関数との違いも解説
1. 確率密度関数とは?
確率密度関数(PDF)は、ある範囲内で確率変数がどのように分布するかを表す関数です。
確率密度関数の値自体は「確率」を直接示すものではなく、ある区間内に確率変数が収まる確率は、確率密度関数をその区間で積分することで求められます(大事)
例えば、確率変数 ${X}$ が区間 ${a}$ から ${b}$ に収まる確率 ${P(a \leq X \leq b)}$ は、以下の式で計算されます。
$${P(a \leq X \leq b) = \int_{a}^{b} f(x)dx}$$
この概念を直感的に理解するために、「人口密度」に例えることができます。
ある都市の人口密度マップを考えたとき、特定の地点の人口密度が高いからといって、その地点に多くの人がいるとは限りません。

しかし、特定のエリア内の人口を求めるには、その地域の人口密度を積分すればよいのです。
同じように、確率密度関数の値 ${f(x)}$ は「確率の密度」を示し、実際の確率は積分によって求められます。
2. 確率密度関数の特性
確率密度関数は次の 2 つの重要な性質を持ちます。
- 非負性: すべての ${x}$ に対して ${f(x) \geq 0}$ が成り立つ。
- 確率の総和が 1: 確率変数がどこかの値を取る確率は 100% であるため、PDF の全範囲での積分は 1 になる。
$${\int_{-\infty}^{\infty} f(x)dx = 1}$$
このあたりは、確率として当たり前の特性ですね。
3. 代表的な確率密度関数
確率密度関数にはさまざまな種類がありますが、代表的なものをいくつか紹介します。
いずれも確率分布可視化ツールでぬるぬる動かせるので、ぜひ試してください!!
3.1. 一様分布
$${f(x) = \begin{cases} \frac{1}{b – a}, & (a \leq x \leq b) \\ 0, & \text{otherwise} \end{cases}}$$
- 特徴: 指定された範囲内で均等に分布。
- 例: 0 から 1 の間でランダムな数値を生成する場合。
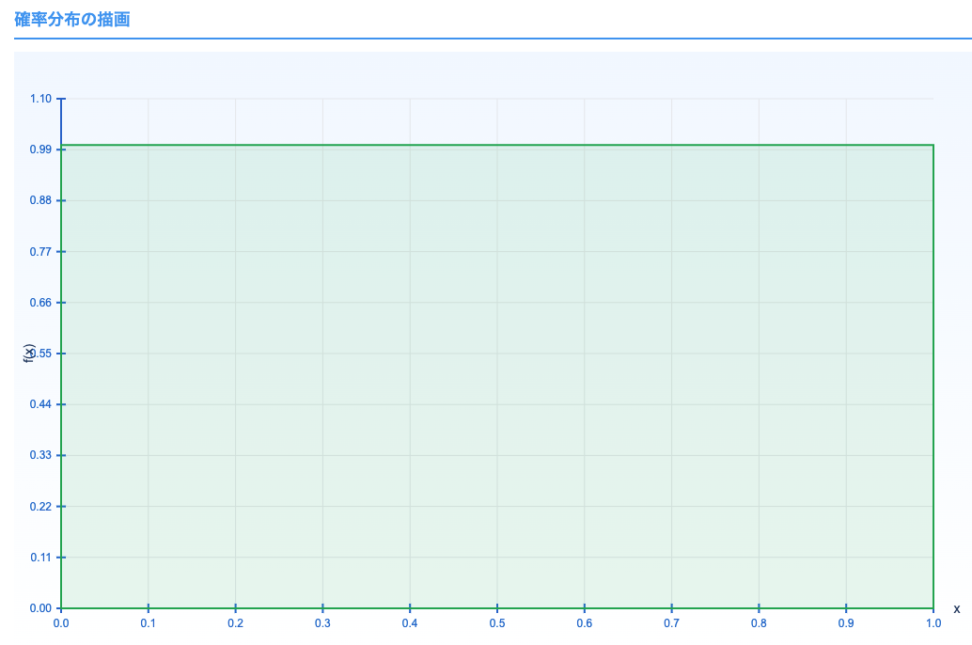
確率を求める手順は次の通りです
- 確率を求めたい範囲 (${c}$ から {d}$) を決める。
- 積分を計算 する。
なので、一様分布$ {U(0,1)}$においては、
$${P(0.3 < X < 0.7) = 0.7 – 0.3 = 0.4}$$
などとなります。
3.2. 正規分布
$${f(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x – \mu)^2}{2\sigma^2}}}$$
- 特徴: 釣鐘形を持つ。
- ${\mu}$ は平均、${\sigma}$ は標準偏差。
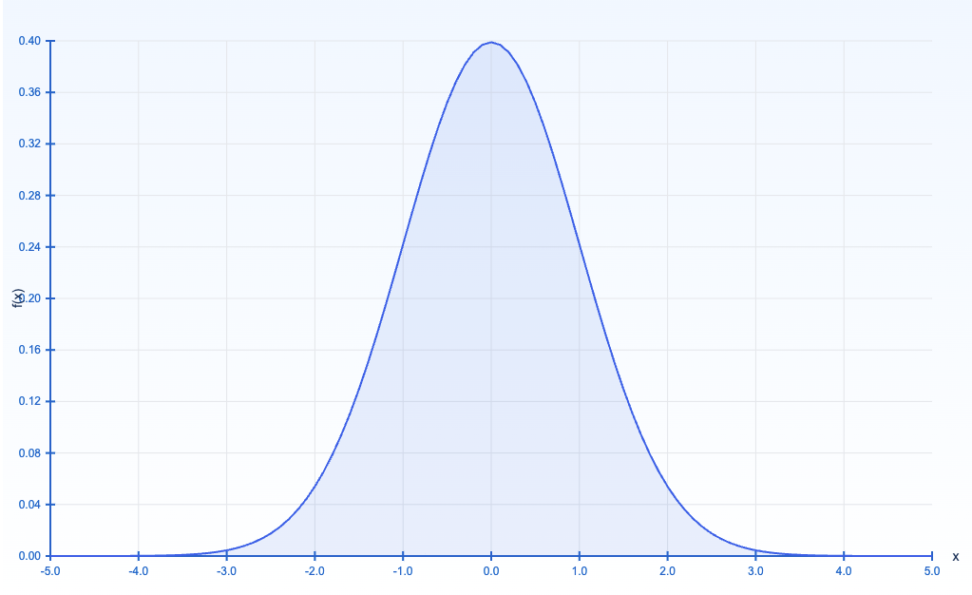
正規分布 ${N(50, 10^2)}$ において、${P(40 < X < 60)}$ を求めてみましょう。
- zスコアを求める
- ${z = \frac{40 – 50}{10} = -1, \quad z = \frac{60 – 50}{10} = 1}$
- 標準正規分布表を使う
- ${P(-1 < Z < 1) \approx 0.6826}$
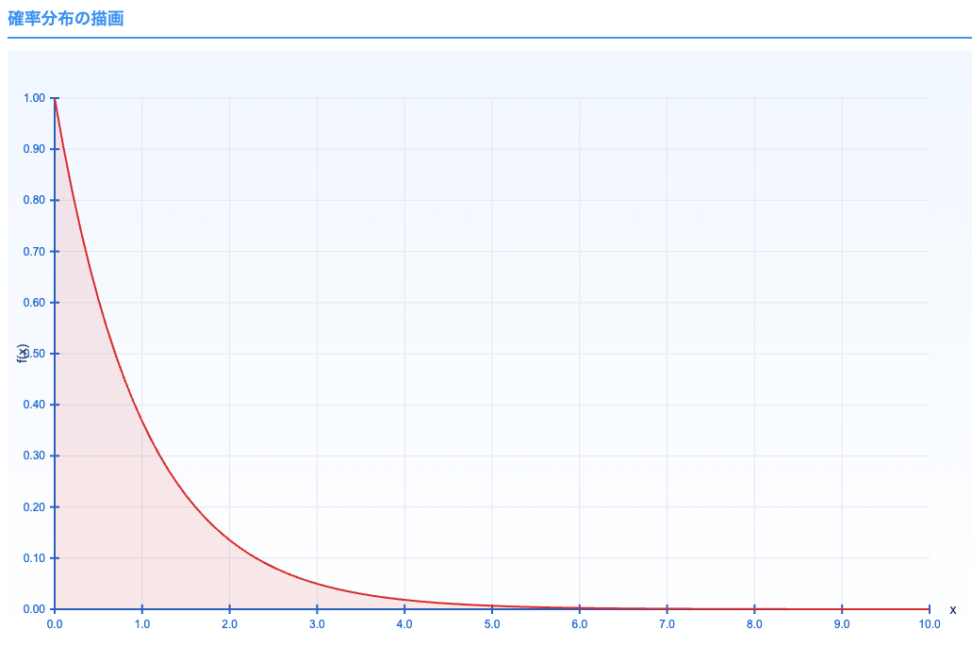
3.3. 指数分布
$${f(x) = \begin{cases} \lambda e^{-\lambda x}, & (x \geq 0) \\ 0, & \text{otherwise} \end{cases}}$$
- 特徴: メモリレス性を持ちます。無記憶性ともいいますね。
4 累積分布関数とは?
累積分布関数 とは、確率変数が特定の値 以下 である確率を表す関数です。
ある確率変数 ${X}$ に対して、累積分布関数 ${F(x)}$は次のように定義されます。
$${F(x) = P(X \leq x) = \int_{-\infty}^{x} f(t)dt}$$
確率密度関数${f(x)}$ を ${-∞}$ から ${x}$ まで積分したものであり、「左側の確率の合計」を意味します。
確率密度関数は 局所的な確率密度 を示すのに対し、累積分布関数は 累積的な確率 を示す曲線になります。
4.1.累積分布関数の性質
- 単調非減少関数: ${F(x)}$ は ${x}$ が増加するにつれて減ることはなく、常に増加または一定。
- 確率の範囲: 累積分布関数は 0 から 1 の間の値をとる。
- ${F(-∞) = 0}$
- 確率変数が最小値より小さい確率は 0
- ${F(∞) = 1}$
- 確率変数が取り得る最大値以下の確率は 100%
- ${F(-∞) = 0}$
4.2. 累積分布関数と 確率密度関数 の関係
確率密度関数(PDF)は、累積分布関数の微分を取ることで得られます。
$${f(x) = \frac{d}{dx}F(x)}$$
これは、累積分布関数の傾きが確率密度関数の値に対応することを意味します。
つまり、累積分布関数の増加が急な部分では、確率密度関数の値が大きく、累積分布関数の増加が緩やかな部分では、確率密度関数の値が小さいことを示します。
正規分布の場合
- 平均値付近では累積分布関数が急激に増加する(→ 確率密度関数 のピークがある)
- 両端では累積分布関数の増加が緩やか(→ 確率密度関数 の値が小さい)
4.3. 累積分布関数の具体例
例 1: 一様分布 ${U(a, b)}$
一様分布の PDF
$${f(x) = \begin{cases} \frac{1}{b-a}, & (a \leq x \leq b) \\ 0, & \text{otherwise} \end{cases}}$$
一様分布の累積分布関数
$${F(x) = \begin{cases} 0, & x < a \\ \frac{x-a}{b-a}, & a \leq x \leq b \\ 1, & x > b \end{cases}}$$
一様分布の CDF は線形に増加し、${x = a}$ で 0、${x = b}$ で 1 になります。
例 2: 正規分布 ${N(\mu, \sigma^2)}$
正規分布の確率密度関数
$${f(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x – \mu)^2}{2\sigma^2}}}$$
正規分布の累積分布関数
正規分布の累積分布関数 ${F(x)}$ は、積分の解析的な解が存在しないため、数値積分 や 標準正規分布表 を用いて求めます。
$${F(x) = \frac{1}{\sqrt{2\pi}} \int_{-\infty}^{x} e^{-t^2/2}dt}$$
このため、正規分布の確率を求める際には標準正規分布表を参照することが一般的です。


5 確率質量関数との違い
確率密度関数と確率質量関数は、連続型確率変数と離散型確率変数 の違いに基づいて区別されます。
5.1.確率質量関数とは?
確率質量関数は、離散型確率変数 に対して定義され、特定の値を取る確率を直接示します。
例えば、サイコロを振る場合、確率変数 ${X}$ が 1, 2, 3, 4, 5, 6 のいずれかを取る確率は、
$${P(X = x) = \frac{1}{6}, \quad (x = 1, 2, 3, 4, 5, 6)}$$
確率質量関数は個々の値ごとに「点の高さ」として表現されます。
5.2.確率密度関数と確率質量関数の違い
確率質量関数は、離散型確率変数に適用される概念であり、特定の値を取る確率を直接表すということですね。
例えば、コインを 10 回投げて表が 3 回出る確率 ${P(X=3)}$ は、確率質量関数によって直接計算できます。
一方、確率密度関数は 連続型確率変数に適用され、特定の値を取る確率は ゼロ になります。
例えば、「身長がちょうど 170 cm である確率」は 0 です。
なぜなら、連続分布では、無限に細かい値が存在するため、1 点を取る確率は限りなく小さくなります。
| 確率密度関数(PDF) | 確率質量関数(PMF) | |
|---|---|---|
| 適用対象 | 連続型確率変数 | 離散型確率変数 |
| 関数の性質 | 微分可能 | 離散的(点ごとに定義) |
| 確率の求め方 | 積分: ${P(a \leq X \leq b) = \int_a^b f(x)dx}$ | 和: ${P(X = x) = p(x)}$ |
| 例 | 正規分布、指数分布 | 二項分布、ポアソン分布 |

青の統計学は、東京大学を卒業後、事業会社でデータサイエンティストとして勤務する筆者が運営する、AI・データサイエンスの総合学習メディアです。 自身の大学時代の経験から、教科書だと分かりにくかった事項を克服でき、かつ実務で活かせる知識を楽しく学べるように、インタラクティブ学習ツール「DS Playground」を開発しており、大学での講義の材料としても利用されています。Xフォロワー1万人を突破!

