【API】Google Search Consoleから1000行以上の検索クエリを取得したい|Google Cloud
こんにちは、青の統計学です。
今回は、掲題の通りサーチコンソールから検索クエリをたくさんとる方法についてまとめていきます。
業務で使う機会があったので備忘がわりです。
Google Cloudで行うこと
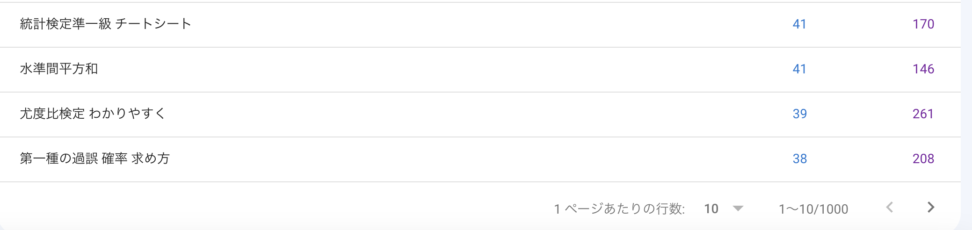
Search consoleだと、1000行までの検索クエリしか取れません。
青の統計学でさえ1000行を遥に超えているので、たいていの企業のサイトや中規模以上のブログなどは、1000行を超えてくるはずです。
ここの検索クエリをもっと多くとって、検索者の意図をより正確に把握し、サイトの磨き込みをする上での意思決定につなげたいですね。
①Google Cloudでプロジェクトを作成する。
まずは、Google Cloudでプロジェクト作成します。
Googleアカウントさえ持っていれば無料で利用できますので以下のURLからプロジェクトを作成しましょう。
Google Cloud Platformで プロジェクトを作成する
②Google Search ConsoleのAPIを登録する
Google Cloud Platformでプロジェクトが作成できたら、次はGoogle search consoleのAPIを登録していきます。
以下のURLからGoogle search consoleのAPIを登録していきましょう。
Google search consoleの APIを登録する
ちゃんと作ったプロジェクトのIDと紐づいているか確認してくださいね。
③サービスアカウントの設定
さて、プロジェクトの下にはサービスアカウントを作る必要があります。
以下のURLからプロジェクトに紐づくサービスアカウントを作成してください。
補足|プロジェクトとサービスアカウントの構造
プロジェクト: プロジェクトはGCPリソースのコンテナとして機能します。
アプリケーション、サービス、ビルド、API利用、請求など、すべてのリソースはプロジェクトに関連付けられます。
サービスアカウント: これは特定のプロジェクト内で作成されるアカウントで、GCP内のサービスが互いに(または外部サービスがGCPリソースに)安全にアクセスするために使用されます。
サービスアカウントは、普通のgoogleアカウントとは異なり、アプリケーションやサービスがGCPのAPIにアクセスするために使用されます。
APIとサービス: 各プロジェクト内で、Google CloudのさまざまなAPIやサービスを有効化して利用できます。
例えば、Google Compute Engine, Google Kubernetes Engine, Google BigQueryなどがあります。
サービスアカウントの役割
さて、その上でサービスアカウントは以下のような役割があります。
特定のプロジェクト内のリソースに対する認証と権限付与
例えば、Google Search Console APIにアクセスするために使用されるサービスアカウントは、適切な認証情報(通常はJSON形式のキーファイル)を用いてAPIリクエストを認証します。←大事。
したがって、Google Cloudでプロジェクトを作成し、そのプロジェクト内でサービスアカウントを作成・管理することになります。
これにより、GCPのリソースやサービスに安全にアクセスできるようになります。
④キーの設定とjsonファイルのダウンロード
Google cloud内でやることはこれで最後です。
今回はjupyter などのローカル環境からAPIを呼び出すことを想定しているので認証情報が必要です。
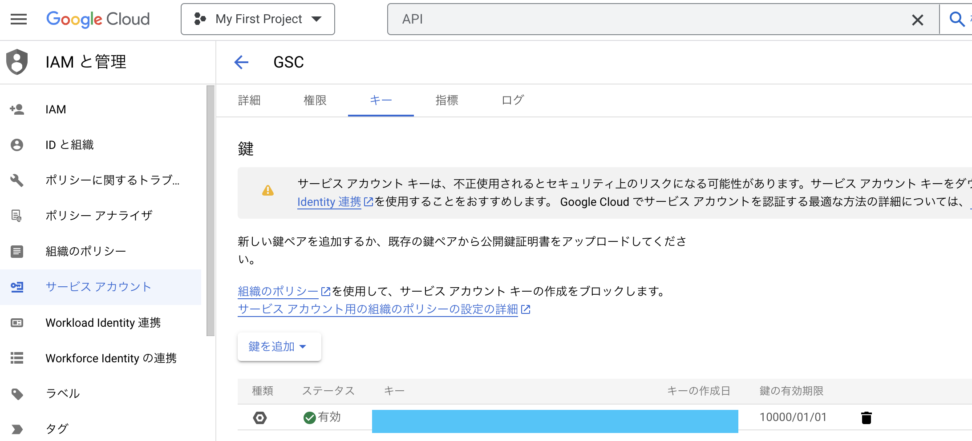
利用予定のサービスアカウントの詳細設定に、キーの設定ができる項目があり、そこから設定できます。
同時にキーの情報が載っているjsonファイルをダウンロードしてください。
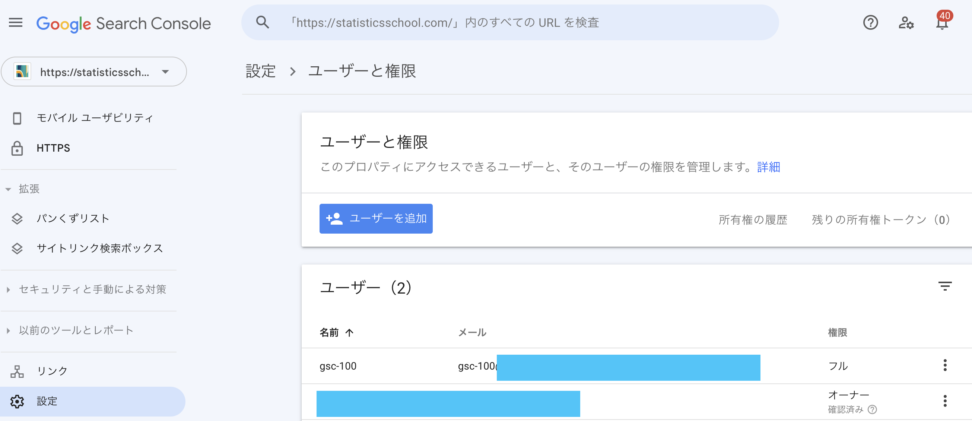
Search Consoleでやること
さて、ご自身のサイトがSerach Consoleと連携済みであることは前提ですが、下記設定画面で先ほど作成したサービスアカウントのメアドを登録します。
Google Cloud Platformで作成したサービスアカウントのメールアドレス(通常は xxxx@your-project-id.iam.gserviceaccount.com の形式)が、Google Search Consoleの該当サイトのオーナーまたはユーザーとして追加されているか確認してください。
これで準備は完了です。
google search consoleのAPIを使って、検索クエリを呼び出してみましょう。
CODE
pip install google-api-python-client oauth2clientgoogle-api-python-client と oauth2client ライブラリをインストールする必要があります。これらはPythonでGoogleのAPIを使用する際に必要です。
from googleapiclient.discovery import build
from oauth2client.service_account import ServiceAccountCredentials
# 定義
SCOPES = ['https://www.googleapis.com/auth/webmasters.readonly']
KEY_FILE_LOCATION = 'ダウンロードしたjsonの場所をおいてね!'
SITE_URL = 'ご自身のサイトのURLをおいてね!'
# Search Console APIクライアントの初期化
credentials = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION, SCOPES)
webmasters_service = build('searchconsole', 'v1', credentials=credentials)
# リクエスト
request = {
'startDate': '2023-01-01',
'endDate': '2023-01-31',
'dimensions': ['query'], # 取得するデータの種類(ここではクエリ)
'rowLimit': 12 # 取得する行の最大数。
}
# 実行
response = webmasters_service.searchanalytics().query(siteUrl=SITE_URL, body=request).execute()
# 結果の表示
for row in response.get('rows', []):
query = row['keys'][0]
clicks = row['clicks']
impressions = row['impressions']
ctr = row['ctr']
position = row['position']
print(f"Query: {query}, Clicks: {clicks}, Impressions: {impressions}, CTR: {ctr}, Position: {position}")今回は12行だけ呼び出します
2023年1月における青の統計学がインプレッションされた検索クエリは以下のようになりました。
Query: 尤度比検定 r, Clicks: 30, Impressions: 79, CTR: 0.379746835443038, Position: 2.8987341772151898 Query: python コレログラム, Clicks: 7, Impressions: 48, CTR: 0.14583333333333334, Position: 5.229166666666667 Query: ブートストラップ法 python, Clicks: 7, Impressions: 59, CTR: 0.11864406779661017, Position: 5.067796610169491 Query: r 尤度比検定, Clicks: 5, Impressions: 19, CTR: 0.2631578947368421, Position: 3 Query: 傾向スコアマッチング python, Clicks: 5, Impressions: 108, CTR: 0.046296296296296294, Position: 9.101851851851851 Query: コレログラム python, Clicks: 4, Impressions: 56, CTR: 0.07142857142857142, Position: 5.017857142857143 Query: 尤度比検定, Clicks: 4, Impressions: 23, CTR: 0.17391304347826086, Position: 28.043478260869566 Query: スピアマンの順位相関係数 外れ値, Clicks: 3, Impressions: 35, CTR: 0.08571428571428572, Position: 5.8 Query: ブートストラップ python, Clicks: 3, Impressions: 25, CTR: 0.12, Position: 7.08 Query: コサイン類似度, Clicks: 2, Impressions: 275, CTR: 0.007272727272727273, Position: 14.476363636363637 Query: python bonferroni, Clicks: 1, Impressions: 2, CTR: 0.5, Position: 16.5 Query: python t検定, Clicks: 1, Impressions: 14, CTR: 0.07142857142857142, Position: 19.857142857142858
CTR(クリック率)や検索順位なども含めて出力できました。
python関連や、統計学の専門用語に関するクエリに引っ掛かりますね。
5000という制約はありますが、期間フィルタやディレクトリフィルタができるので、困らないと思います。
プライベートキーを使う場合のCODE
jsonファイルをダウンロードしてapiを呼び出すのが一般的ですが、private_keyとprivate_idを使う方法もあります。
ServiceAccountCredentials.from_json_keyfile_dict()メソッドを使います。
ここではより実践的に、1週間に5000行ずつ検索クエリを取得して、1年間分の検索クエリをデータフレームに格納してcsvにするコードを置いておきます。
import pandas as pd
from datetime import datetime, timedelta
# 定義
SCOPES = ['https://www.googleapis.com/auth/webmasters.readonly']
KEY_DICT = {
"type":"sevice_account",
"project_id":"PROJECT_ID",
"private_key_id":"PRIVATE_KEY_ID",
"private_key":"PRIVATE_KEY",
"client_id":"CRIENT_EMAIL",
"client_id":"CLIENT_ID",
"auth_uri":"https://accounts.google.com/o/oauth2/v1/certs",
"token_uri":"https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url":"CLIENT_X509_CERT_URL"
}
SITE_URL = 'ご自身のサイトのURLをおいてね!'
# Search Console APIクライアントの初期化
credentials = ServiceAccountCredentials.from_json_keyfile_name(KEY_DICT, SCOPES)
webmasters_service = build('searchconsole', 'v1', credentials=credentials)
df = pd.DataFrame()
start_date = datetime(2022, 10,1)
end_date = datetime(2023, 9,30)
while start_date <= end_date:
requests = {
"startDate":start_date.strtime("%Y-%m-%d"),
"endDate": (start_date + timedelta(days=7)).strtime("%Y-%m-%d"),
"dimensions":["query"],
"row_limit": 5000
}
response = webmasters_service.serchanalytics().query(siteUrl=SITE_URL, body=request).execute()
for row in response.get("rows", []):
query = row["keys"][0]
clicks = row["clicks"]
impressions = row["impressions"]
ctr = row["ctr"]
position = row["position"]
df =pd.concat([df, pd.DataFrame({
"Query": [query],
"Clicks": [clicks],
"Impressions": [impressions],
"CTR": [ctr],
"Position": [position]})],ignore_index=True)
start_date += timedelta(days=7)
df.to_csv("data.csv", index=False)SEOとLis広告
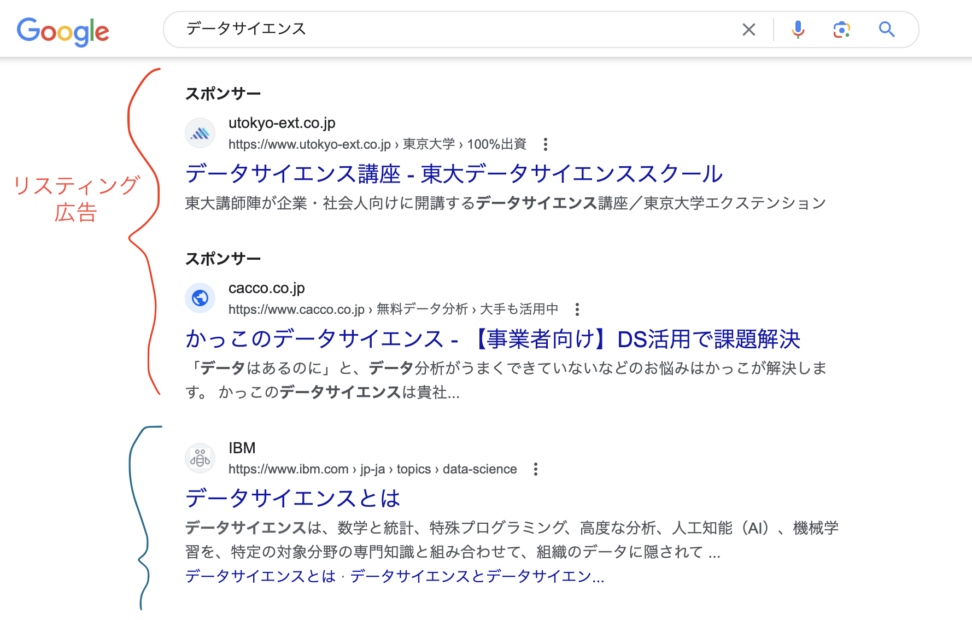
業務的な話ですが、Google Adsの「検索語句」だと有料集客(うちリスティング広告)が引っかかった検索クエリしか出ません。
なので、キーワード設定をしたり広告グループとして注力している検索クエリのみ表示されて、サイトにヒットする検索者のインテント全体までは推し量れないです。
検索面で言うと、上位にくるためリスティング広告とSEOはカニバリ(相殺)が発生します。
棲み分けは大事ですが、「この検索クエリはリスティングで取りに行った方が良い」「収益性のひくい、このクエリはSEOで任せる」といった戦術にまでデータを生かすことができます。
最後に
データサイエンティストに任せられることは、整形済みのデータを使って分析やモデル構築を行うことだけではないです。
→というか、それだけだとGPTをはじめとした生成AIの方が精度もスピードも段違いなので仕事がなくなります。
どれだけ事業に課題感をもち、データに基づいた意思決定を行わせるために、問いに対して必要なアウトプットを持ってくるか、にデータサイエンティストの真髄があると思います。
なので、必要に応じてデータを自分で取りに行って、前処理なりデータ整形なりを行い、どんどん業務的に染み出していくことも生き残る上で必要なのではと思う次第です。

