【R^2】決定係数をわかりやすく説明|python
こんにちは、青の統計学です。
今回は、決定係数について解説します。
決定係数(coefficient of determination)とは
決定係数とは、回帰モデルの説明力を表す指標の一つです。
もっと厳密にいうと、予測値と観測データの相関係数のことを重相関係数と呼びますが、決定係数は重相関係数の2乗に当たります。
$$R^2 = {\frac{\sum_{t}({\hat{y}_t}-{\overline{y}})^2}{\sum_{t}(y_{t}-{\overline{y}})^2}}=(corr(y,{\hat{y}}))^2$$
回帰については、こちらをご覧ください。


算出と評価の手順は以下のとおりです。
①予測値と実際のデータとの相関係数を求めます。
②この相関係数を2乗したものを決定係数\(R^2\)とします。
③1に近いほどモデルの当てはまりが良いと判断する。モデル間の比較に使います。
CODE|python
ここでは簡単な線形回帰モデルを構築し、その決定係数を計算して確認するための Python コードの例を以下に示します。
この例では、sklearnライブラリを使用して回帰モデルを構築し、ランダムに生成されたデータセットに適用します。
まずは、必要なライブラリをインポートしてデータを生成した後、生成したデータに基づいて線形回帰モデルを構築し、学習します。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
# データの生成
np.random.seed(0) # 乱数のシードを設定
x = np.random.rand(100, 1) * 100 # 0から100までのランダムな数
y = 3 * x + np.random.randn(100, 1) * 10 + 50 # 線形関係にランダムノイズを加える
# データのプロット
plt.scatter(x, y, alpha=0.5)
plt.title("Generated Data")
plt.xlabel("x")
plt.ylabel("y")
plt.grid(True)
plt.show()
# 線形回帰モデルの構築と学習
model = LinearRegression()
model.fit(x, y) # モデルの学習
# 予測値の計算
y_pred = model.predict(x)
# 学習データと回帰直線のプロット
plt.scatter(x, y, alpha=0.5, label='Original data')
plt.plot(x, y_pred, color='red', label='Fitted line')
plt.title("Linear Regression")
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.grid(True)
plt.show()

このようにデータのプロットとそれに対する回帰直線の描画ができたと思います。
最後にモデルの性能を評価するために、決定係数 \(R^2\)を計算します。
# 決定係数 R^2 の計算
r2 = r2_score(y, y_pred)
print(f"The R^2 score of the model is: {r2:.2f}")
The R^2 score of the model is: 0.99
当てはまりがかなり良いようです。
数学的な説明
まず、この図を見てください。
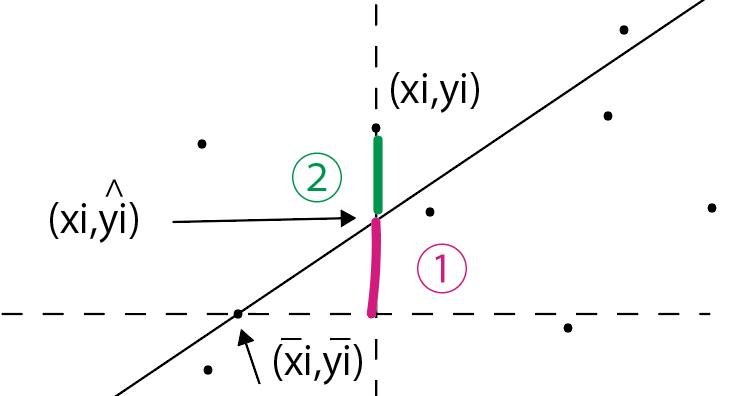
実際にプロットされた点\((x_i,y_i)\)から、\(x\)軸に向かって垂線を引いてみましょう。
回帰直線とぶつかる点があるはずです。
この点は、先ほどの点\((x_i,y_i)\)と「\(x\)座標は同じでも、\(y\)座標は異なる」点です。
この\(y\)座標は、「推定値」です。
2つの点の\(y\)座標の差(図では②)を「残差変動」と呼びます。
また、実際のデータ\(x\)と\(y\)の平均値をとった点と\(y\)座標での差(図では①)を「回帰変動」と呼びます。
この残差変動と回帰変動の和を、「全変動」と呼びます。\(y_i\)の分散を\(n\)倍したものと一致します。
$$\sum_{i=1}^N(y_{i}-{\overline{y}})^2$$
以上は全変動(TSS)です。
$$\sum_{i=1}^N(\hat{y}_i-{\overline{y}})^2$$
以上は回帰変動(ESS)です。
$$\sum_{i=1}^N(y_{I}-{\hat{y}})^2$$
以上は残差変動(RSS)です。
$$TSS=RSS+ESS$$
では、この式から決定係数を出してみましょう。
$$ESS=TSS-RSS$$
回帰変動 = 全変動 – 残差変動 となりました。
次に、全変動で両辺を割ってみましょう。
$$R^2 = {\frac{回帰変動}{全変動}}=1-{\frac{残差変動}{全変動}}$$
$$R^2 = {\frac{ESS}{TSS}}=1-{\frac{RSS}{TSS}}$$
上のようになったと思います。
1から残差変動と全変動の商を引いています。
また、決定係数とは、回帰変動を全変動で割った値のことを言います。
\(\frac{回帰変動}{全変動}\)の分母と分子を\(n-1\)で割ることで、決定係数は予測値の分散を目的変数の観測データの分散で割ったものだと判断できます。
決定係数とは、「回帰直線はどの程度データを説明できているかを図る指標の一つ」でした。
回帰変動がどれだけ全変動を説明できているかが、モデルの信用度に関わるということになります。
逆に言えば「推定量と実際のデータの差」である残差変動が大きいほど、予測という面に関しては残念なモデルと言わざるを得ないということです。
決定係数が1に近すぎる場合
サンプルデータが少ない場合に過学習を起こし、決定係数がほぼ1になってしまうことは一般的な問題です。以下の方法を試すことで過学習を防ぐことができます。
正則化
正則化は、過学習を防ぐために使用されます。正則化は、モデルの複雑度を制限することで、過学習を防ぎます。例えば、L1正則化やL2正則化などがあります。
【python】Ridge(リッジ)回帰で多重共線性を解決する話
【python】Lasso(ラッソ)回帰で疎なデータに対応しよう|機械学習
交差検証
交差検証は、過学習を検出するために使用されます。交差検証は、トレーニングデータとテストデータの両方でモデルを評価し、過学習が起きていないかを確認します。
データ拡張
データ拡張は、サンプルデータの数を増やすために使用されます。
既存のデータを変形、回転、反転などして新しいデータを生成することで、サンプルデータの数を増やします。
アンサンブル学習
アンサンブル学習は、複数のモデルを組み合わせることで、過学習を防ぐために使用されます。
バギング、ブースティングなどの方法があります。
この辺りの記事が参考になると思います。
新しいデータを収集する
サンプルデータが少ない場合に新しいデータを収集することで、モデルの汎化性能を上げることができます。
追記:残差と誤差項の違いは?
残差と誤差項の違いは、数式を見ると明らかでしょう。
$$Y_{i}-{\hat{Y}_{i}}$$
こちらは残差です。
残差は、実際の観測データから推定量を引いたものです。
$$Y_{i}=β_{0}+β_{1}X_{i}+ε_{i}$$
こちらは誤差項です。
誤差項は、統計モデルにおける説明変数と定数項以外の部分です。
正規分布に従うと仮定されることが多いです。
自由度調整済み決定係数(adjusted R^2)
決定係数は、その性質上「説明変数を増やせば増やすほど」値が高くなります。
このため、多変量になった時にover fittingされたモデルが「良いモデル」として評価されてしまうことになります。
1980年代や1990年代では、説明変数を増やしまくって「データとの当てはまりが良いと」評価されるモデルが疑問視されたという経緯があったりします。
決定係数は、モデルを評価する指標の一つであると理解しておきましょう。
そこで、導入された指標が「自由度調整済み決定係数」です。
特徴量(次元d)が増えれば増えるほど、ペナルティを受けるという設計になっています。
以下のように、分母を\(n-1\)でわり、分子を\(n-d-1\)で割っています。
$$adjustedR^2 = 1-{\frac{\frac{\sum_{i=1}^{N}(y_{i}- \hat{y}_{i})^2}{n-d-1}}{\frac{\sum_{i=1}^{N}(y_{i}-{\overline{y}})^2}{n-1}}}$$
これは回帰変動と総変動、残差変動の自由度をそれぞれ使っているだけです。
総変動の自由度は、サンプル数-1
回帰変動の自由度は、説明変数の数
残差変動の自由度は総変動の自由度-回帰変動の自由度で求められます。
$$adjusted R^2=1-(\frac{\frac{残差変動}{残差変動の自由度}}{\frac{総変動}{総変動の自由度}})=1-(1-R^2)×\frac{総変動の自由度}{残差変動の自由度}$$
調整してない決定係数を使って、こんなふうに表すこともできます。
決定係数を使って調整済み決定係数を算出する問題は統計検定準一級でも出ています。
決定係数を評価指標に入れるときは、「被説明変数の予測精度を重視するとき」だと考えてください。
これに対して、「説明変数の影響を正しく知る」ことを目的にしたとき、欠落変数のバイアスを避けるために、説明変数をできるだけ入れようとします。
これによって、自由度調整済み決定係数が下がったとしても、特に問題はありません。

決定係数は2乗のイメージがあるため、負にはならないのではないかというイメージがありますが、自由度調整済み決定係数だと負の数にはなり得ます。
残差の変動が大きく、自由度で調整した結果負になるからですね。
目的に応じて機械学習の評価指標は使いましょう。
欠落変数のバイアスについては、以下のコンテンツをご覧ください。
統計検定のチートシートは以下をクリック!

青の統計学は、東京大学を卒業後、事業会社でデータサイエンティストとして勤務する筆者が運営する、AI・データサイエンスの総合学習メディアです。 自身の大学時代の経験から、教科書だと分かりにくかった事項を克服でき、かつ実務で活かせる知識を楽しく学べるように、インタラクティブ学習ツール「DS Playground」を開発しており、大学での講義の材料としても利用されています。Xフォロワー1万人を突破!
