【自然言語処理】単語の出現頻度を可視化させてみましょう | python
今回は、形態素解析した単語たちを出現頻度ごとに集計してグラフ化させてみます。
アンケートや問い合わせの文言から、どんなキーワードがユーザーの不満や満足に繋がっているのかという示唆を得られる点では、かなり実務的なスキルになります。
自然言語に関して、形態素解析からやり直したい方は、【自然言語処理】形態素解析で文章を単語に分けてみましょう。をご覧ください。
前回よりも、コードの解説を丁寧に行います。
単語の出現頻度の可視化
import MeCab
import pandas as pd
txt ="自然言語処理は、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能と言語学の一分野である。計算言語学との類似もあるが、自然言語処理は工学的な視点からの言語処理をさすのに対して、計算言語学は言語学的視点を重視する手法をさす事が多い。データベース内の情報を自然言語に変換したり、自然言語の文章をより形式的な表現に変換するといった処理が含まれる。応用例としては予測変換、IMEなどの文字変換が挙げられる。自然言語の理解をコンピュータにさせることは、自然言語理解とされている。自然言語理解と、自然言語処理の差は、意味を扱うか、扱わないかという説もあったが、最近は数理的な言語解析手法が広められた為、パーサなどが一段と精度や速度が上がり、その意味合いは違ってきている。もともと自然言語の意味論的側面を全く無視して達成できることは非常に限られている。このため、自然言語処理には形態素解析と構文解析、文脈解析、意味解析などをSyntaxなど表層的な観点から解析をする学問であるが、自然言語理解は、意味をどのように理解するかという個々人の理解と推論部分が主な研究の課題になってきており、両者の境界は意思や意図が含まれるかどうかになってきている。"
#分かち書き
tagger = MeCab.Tagger('-Owakati')
print(tagger.parse(txt))まずは、前回と同じようにMeCabというライブラリを使います。
また、今回はwikipediaの「自然言語処理」の概要を使ってみます。
txtという変数に文字として代入します。
今回は、「分かち書き」をやってみます。taggerの「-Owakati」を使うと下のように、分かち書きされた状態で出力されます。
分かち書きとは、文章の区切り(品詞など)ごとに空白を入れて記述することです。
英語などは、自然に単語ごとに分かちされていますが、日本語はされていません。

#形態素解析
tagger = MeCab.Tagger()
parsed_txt = tagger.parse(txt)
elements = parsed_txt.split('\n')[:-2]
elementsでは、形態素解析を行なってみます。
tagger.parseのパースとは、プログラムが扱えるようなデータ構造に変えるという意味を持ちます。
また、split(“\n”)[:-2]とは、下から2行分を削除して、改行コードごとに改行して出力しているということです。
区切り文字で分割している方が、すっきりしていてみやすいですね。
自然言語処理では、split関数を多用しますので覚えても良いでしょう。
下から2行消したのは、今回入力した文章とは関係ない、EOSと” “を消すためです。
ちなみにEOSとは、end of sentenceの略であり、文章の終わりを表しています。

#名詞のみを抽出してみます。
all_words = []
parts = ["名詞"]
stop_words = ["の"]
words = tagger.parse(txt).splitlines()
words_arr = []
for i in words:
if i == "EOS" or i=="":continue
word_tmp = i.split()[0]
part = i.split()[1].split(",")[0]
if not (part in parts):continue
#stop_wordsだった場合に、words_arrに加えないようにする。
if word_tmp in stop_words:continue
words_arr.append(word_tmp)
all_words.extend(words_arr)
words_arrでは、本題の名詞のみを抽出して、出現頻度を調べてみます。
「の」が紛れて名詞として扱われてしまうため、stop_wordsとして登録して、words_arrに追加されないようにプログラムを書いています。

しかし、これでは重複が存在しますね。同じものはちゃんとカウントして集計しましょう。
all_words_df = pd.DataFrame({"words":all_words,"count":len(all_words)*[1]})
all_words_df = all_words_df.groupby("words").sum()
all_words_df.sort_values("count",ascending=False)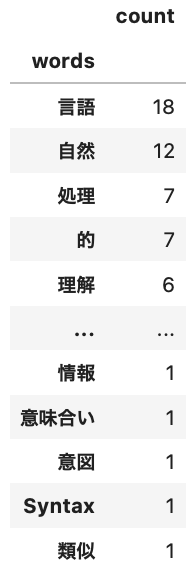
このような出力結果になりました。自然言語処理についての文章なので、上位三つは予想通りですね。他には、「的」や「理解」が多く登場していることがわかります。
本を何冊も分析にかけて、著者のよく使う文字を見つけてみるのも楽しいかもしれません。
可視化
では、matplotlibを使って可視化してみましょう。
#ライブラリのインポート
!pip install japanize_matplotlib
import matplotlib.pyplot as plt
import japanize_matplotlib
%matplotlib inline
from collections import defaultdict
#辞書のバリューがint型
word_freq = defaultdict(int)
for result in results:
if result['品詞'] == '名詞':
word_freq[result["基本形"]] += 1
word_freqpipのインストールは多少時間がかかるかもしれません。

今度は、行列にせず辞書型として保存しました。
key:valueの形で値を保存します。今回は、「名詞:出現回数」ですね。javaだとHashmapも同じような形でデータを保存します。
#単語と回数。回数を基準にする。
#ここでkey=LAMBDA
sorted_word_freq = sorted(word_freq.items(), key=lambda x:x[1], reverse=True)
sorted_word_freq
次にkeyに対応する値を降順で並ばせます。
辞書やリストをsortedする時によく出るのが、lambdaです。
lambdaは、無名関数と呼ばれており、その名のとおり、名前の無い関数を作成する際に使います。
#内包表記
#for 分をリスト形式で書いている
keys = [_[0] for _ in sorted_word_freq[:10]]
#内包表記その2
values = [_[1] for _ in sorted_word_freq[:10]]
plt.figure(figsize=(8, 4))
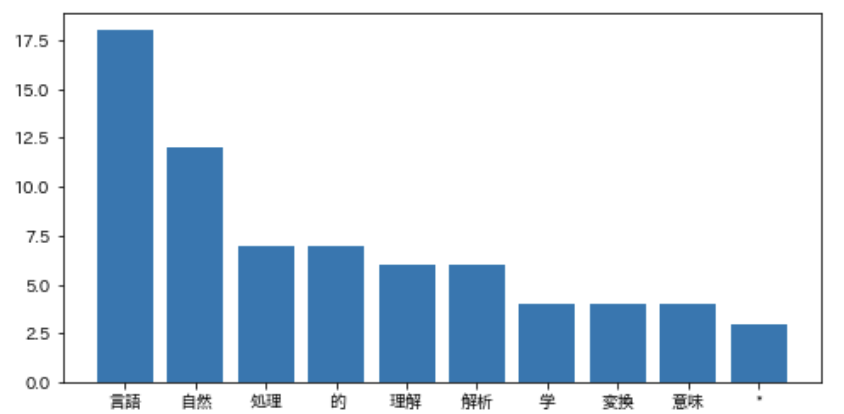
plt.bar(keys, values)
plt.show()上位10単語だけでいいと思うので、10行目までの「単語」をそれぞれ取り出し、keysに入れます。
基本情報技術者試験でも最近でたpythonの内包表現です。for in文はとても便利なので、積極的に使ってみましょう。
内包表記その2では、keysに対応するvalueを取り出します。
図式化に入ります。keysを横軸、valuesを縦軸にします。
視覚的に出現頻度の高い文字を表すことができました。
ちなみに、import japanize_matplotlibを使わないと日本語を使った軸名は設定できないので注意です。
単語の頻度をデータとして扱う以前には、もっと古典的方法として、サンプルの単語数をデータとして捉える手法もありましたが、あまりにも乱暴ですね。
アンケート調査など、社会科学の分野ではテキストをデータとして扱う機会が多いと思います。
単語の数→頻度→語順→各単語の意味合い→文章の意味合い→文脈など、機械が学習できる内容がリッチになればなるほど、観測したデータをきちんととらえたデータ分析ができそうですね。
自然言語処理に興味が湧いた人は、【python】コサイン類似度は高校数学の知識で理解できます!をご覧ください。

青の統計学は、東京大学を卒業後、事業会社でデータサイエンティストとして勤務する筆者が運営する、AI・データサイエンスの総合学習メディアです。 自身の大学時代の経験から、教科書だと分かりにくかった事項を克服でき、かつ実務で活かせる知識を楽しく学べるように、インタラクティブ学習ツール「DS Playground」を開発しており、大学での講義の材料としても利用されています。Xフォロワー1万人を突破!

