ベイズ推定をわかりやすく解説|事後分布から推定量を導く方法
ベイズ推定の目的
ベイズの定理からしっかり解説するので、これからベイズ推定について知見を深めたい人や、MCMC法を使ってベイズ推定をしたい方など、さまざまな人におすすめです。
ベイズの定理
まず第一にベイズ統計学は、経験を数値化し、数学的に扱う手法です。
この手法はベイズの定理に基づいており、過去のデータをもとに現時点の考えを更新することが特徴です。
この考え方をベイズ更新と呼びます。
ベイズ更新の考え方
ベイズ更新は、統計的な推測方法の中でも特に経験に基づいて考えを修正していくプロセスです。
これにより、現時点での事象に対する理解を深め、次の行動に反映させることができます。

例えば、事前確率として、道の角から人が飛び出してくる確率を${0.5}$と仮定します。しかし、ある朝、実際にその状況が発生し、衝突してしまったとします。この経験から、「朝の通勤時間には人が飛び出してくる確率が高い」と考え、翌日はより注意して歩くようになると思います。
ベイズの定理
では、ここでベイズの定理について解説します。
統計検定2級から計算問題でも出てくるので要チェックです。
その前に、事前分布と事後分布について理解をする必要があります。
事前分布と事後分布
事前分布:データが考慮される前のパラメータの確率分布に関する信念を表します
事後分布:観測データなど、取り得るさまざまな値に対する信念の強さを表す分布です。事後分布は、ベイズの定理に即した事前分布、データ、尤度に基づく。
ベイズの定理を先に見ておきましょう。
$${P(\theta|D)=\frac{P(D|\theta)P(\theta)}{\int P(D|\theta)P(\theta)d\theta}}$$
事前確率 $P(\theta)$は初期の仮定や知識で、事後確率 $P(\theta|D)$データを観測した後の更新された信念とわかったものの、もう一つ押さえていただきたい概念が「尤度」です。
これは、${P(D|\theta)}$の部分で、データがどの程度その仮定と一致するかを表しています。
尤度については、青の統計学だとこのあたりの記事がおすすめです。


さて、上は少し直感的すぎるので、もう少し定義に則るとこんな感じです。
- ${P(\theta|D)}$: データ ${D}$ が与えられたときのパラメータ${\theta}$ の事後確率
- ${P(D|\theta)}$: パラメータ ${\theta}$ の下でのデータ $D$ の尤度
- ${P(\theta)}$: パラメータ ${\theta}$ の事前確率
- 分母の積分: 全確率の正規化項
これにより、観測可能なデータを使って観測不能なパラメータを推論できるようになっています。
よくみる形は以下のような単純な条件付き確率を使ったものではないでしょうか。
$$P(A|B)={\frac{P(A)P(B|A)}{P(B)}}$$
求めたい条件付き確率は、逆の条件付き確率を使えば求められる、ことになります。
「逆」というのは、AとBを原因と結果に分けた時にわかりやすくなると思います。
具体例:トトロの発見確率のベイズ更新
では、例を見てみましょう。
メイちゃんは、どうやらトトロをみたらしいです。
しかし、森の中を探しても全然見つかりませんでした。
この時、メイちゃんが嘘つきである確率をベイズの定理を使って求めてください。
情報:
メイちゃんが嘘つきの場合、「実際にトトロが居てもいなくても」、「トトロいたもん!」と出力します。
メイちゃんは普段嘘をつく方ではないので、メイちゃんが嘘つきである事前確率は0.1です。
メイちゃんが正直者の時に、トトロが見つかってしまう確率を0.8とします。
一方、メイちゃんが嘘つきの時にトトロが見つかってしまう確率は0.3とします。
トトロが見つからないとき、こんなパターンがあると仮定しましょう。
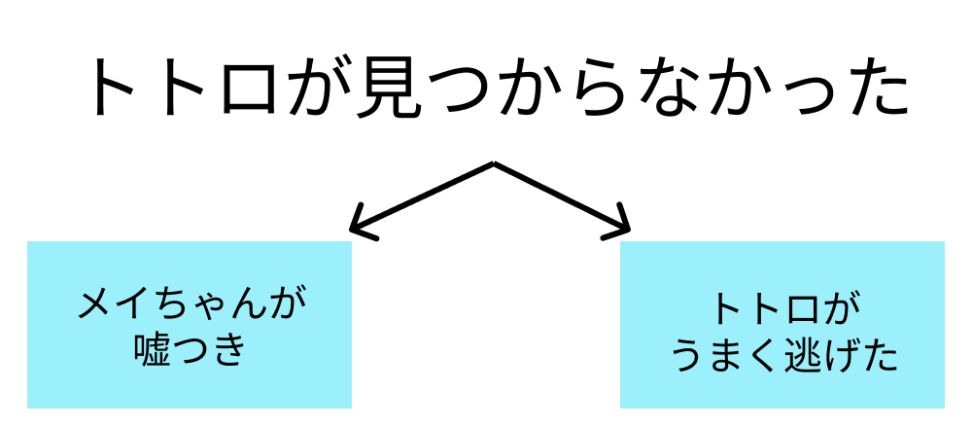
今回求めるのは、以下の条件付き確率です。
$${P(嘘つき|観測できない)}$$
今回の確率は、先程ベイズの定理を使って以下のように求めることができます。
$${p(嘘つき|発見されない)=\frac{p(嘘つき)×p(発見されない|嘘つき)}{p(発見されない)}}$$
メイちゃんが嘘つきの時にトトロが見つかってしまう確率は0.3なので、メイちゃんが嘘つきの時にトトロが見つからない確率は、${1-0.7=0.3}$ですね。これが尤度です。
要は\(P(D|X)\) を \(D\) が観測された(今回はトトロがいなかったという事象)時の \(X\)(メイちゃんが嘘つき) の尤度 (likelihood) と呼んでいます。この尤度に従って、観測結果がサンプリングされているイメージです。
分母:${P(観測できない) = P(観測できない | 嘘つき)*P(嘘つき) + P(観測できない | 正直者)*P(正直者) = 0.1 * 0.7 + 0.9 * 0.2 = 0.25}$
分子:${P(嘘つき)*P(観測できない | 嘘つき) = 0.1 * 0.7 = 0.07 }$
よって、求める確率は${0.28}$です。
求めたい条件付き確率は、逆の条件付き確率を使えば求められる、ことになります。
今回の場合、以下のように、「原因がわかれば結果がわかる」確率を、「結果がわかれば原因がわかる」確率に加工できます。
なので、「トトロが居なかった」という観測結果から、
1「メイちゃんは正直者だが、トトロが逃げた」
2「メイちゃんが嘘つきだった」
という原因の確率を求める、ということになります。
$$P(原因|結果)={\frac{尤度*P(結果|原因)}{P(結果)}}$$
ただ、P(結果)は往々にして計算が大変な場合があります。
今回のように単純な例を除き、事後分布の計算には「マルコフ連鎖モンテカルロ法(MCMC法)」という、「尤度と事前分布の積だけで事後分布を近似させる」という手法がよく使われます。
【完全ガイド】MCMC法についてわかりやすく解説|ベイズ推定
ベイズの定理における、尤度と事前分布と事後分布の関係は以下の通りです。
尤度という「メイちゃんが嘘つきの時に、観測できなかった確率」を使って、事前分布(確率)という「嘘つきの確率」が
事後分布(確率)という「観測できなかったときに、嘘つきの確率」に変わりました
$${事後分布= \frac{事前分布*尤度}{P(結果)}}$$
さて、トトロを観測できなかった時にメイちゃんが嘘つきの確率が10%から28%に上がるとわかりました。
…しっくりこないでしょうか。
「トトロが逃げる確率」や「メイちゃんが嘘つきの事前確率」を決めうちで設定したから、それを元にした確率が微妙に感じられるのは最もでしょう。しかし、ベイズ統計学は試行を繰り返していくことで真価を発揮します。
次のベイズ更新で見ていきましょう。
ベイズ更新
では、もう一度メイちゃんが「トトロいたもん!」と言ってきましたが、どれだけ探してもトトロを観測できませんでした。この時の、メイちゃんが嘘つきの確率を求めてみましょう。
ただし、先ほどの事後確率の情報を使います。
メイちゃんが嘘つきの確率は0.1から0.28にベイズ更新されています。
この時求める確率は以下のようになります。
$${P(観測されない|嘘つき)= \frac{0.28*0.7}{0.28*0.7+0.72*0.2}}$$
これを計算すると、0.576になります。
メイちゃんが嘘つきである確率が、0.1→0.28→0.58となりました。
何回も「トトロいたもん!」と言われても、実際にトトロを観測できないときは、メイちゃんが嘘つきである可能性がどんどん高まることになりますね。
このようにベイズ統計学は、試行結果を繰り返し使って確率を確からしいものに近づける考え方になります。
尤度が基づくモデルについて|階層回帰モデルを例に
では、実践的な話をします。
ここまで出てきた「尤度」は、あるモデルのパラメータが与えられたときに、そのモデルから観測されたデータが得られる確率のことでしたね。
では、どのように尤度は決まり、どのようにその元となるパラメータも決まっていくのでしょうか?
例えば、${i}$番目の生徒のテストの点数(${y_i}$)が、その生徒の能力(${\theta_i}$)、クラスの平均(${\mu}$)、および誤差(${\epsilon_i}$)で表されるとすると、尤度は以下のように表されます。
$$ {p(y_i|\theta_i, \mu, \sigma) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(y_i – \theta_i – \mu)^2}{2\sigma^2}\right) }$$
階層的回帰モデルでは、上の例のように生徒レベルのパラメータ(${\theta_i}$)自体が、ある分布からサンプリングされたものと仮定します。
例えば、(${\theta_i}$)が、平均(${\mu}$)と分散(${\tau^2}$)の正規分布からサンプリングされるとすると、以下のようになります。
$$ {\theta_i \sim N(\mu, \tau^2) }$$
このように、パラメータ自体に確率分布を仮定することで、データの構造の中に複数のレベルの変動を組み込むことができます。
ベイズ推定では、事後分布を求めるために、尤度と事前分布の積を計算します。
階層的回帰モデルの場合、事前分布は、各レベルのパラメータに対して設定する必要があります。
例えば、(${\mu}$)、(${\tau^2}$)、および(${\sigma^2}$)に対して、それぞれ適切な事前分布を設定します。
ベイズ推定における事前分布の設定は、いわばモデルへの「事前知識」の注入であり、事後分布の形状を大きく左右します。特に階層的回帰モデルでは、複数のレベルのパラメータに対して事前分布を設定するため、その影響はより顕著になります。
基本集団レベルの平均である${\mu}$には、正規分布や裾の広いt分布が使われていたりします。
非負となるパラメータは、ガンマ分布が使われたりしますね。
確率分布については、この辺りがおすすめです!


ただ、事前情報がほとんどない場合は、できるだけデータに影響を与えないような「非情報的な事前分布」を選択します。例えば、正規分布の分散を大きく設定したり、ガンマ分布の形状パラメータを小さく設定したりします。

青の統計学は、東京大学を卒業後、事業会社でデータサイエンティストとして勤務する筆者が運営する、AI・データサイエンスの総合学習メディアです。 自身の大学時代の経験から、教科書だと分かりにくかった事項を克服でき、かつ実務で活かせる知識を楽しく学べるように、インタラクティブ学習ツール「DS Playground」を開発しており、大学での講義の材料としても利用されています。Xフォロワー1万人を突破!
