【尤度とは?】最尤法についてわかりやすく解説|最尤推定量
こんにちは、青の統計学です。
今回は、統計学の中で必須の知識「尤度」について解説いたします。
尤度とは?
確率と尤度の違い

まず、尤度を理解するために、皆さんがよく知っている「確率」との違いを明確にしましょう。
確率は「あるモデルやパラメータが与えられたときに、特定のデータが得られる可能性」を表します。例えば、「公平なコインを投げたときに表が出る確率が0.5である」というモデルがあるとき、10回投げて7回表が出る確率は計算できますね。
一方、尤度はその逆の視点に立ちます。既に「観測されたデータ」があるときに、「そのデータが、どのようなモデルやパラメータから生成されたと考えるのが、もっともらしいか」という度合いを示すのが尤度です。
つまり、尤度は「データが与えられたときの、モデルやパラメータの『もっともらしさ』」を測る指標です。
何が重要?
確率は「原因(モデル)から結果(データ)への推論」であるのに対し、尤度は「結果(データ)から原因(モデル)への推論」と考えることができます。手元にあるデータから未知(モデルのパラメータなど)を探るため、この「逆向きの推論」である尤度が重要な役割を果たします
尤度関数の定義
先ほどの尤度を一般化すると、「得られた標本が確率分布Fによってどれだけ生成されやすいのかの指標」と言えます。
そして尤度関数とは、「パラメータ\(\theta\)の推定量を知るため」の関数です。\(\theta\)は未知です。
そして、尤度関数はパラメーターが\(\theta\)の時の密度の積で表されます。
$$L(\theta;X)=f(X_{1};\theta)×…×f(X_{n};\theta)$$
パラメーターが\(\theta\)の時の確率を全て掛け合わせた、この尤度関数を最大にする\(\theta\)を採用します。
周辺確率の積で表されるということですね。
$$L(\theta;x)=\prod_{i=0}^Nf(x_{i})$$
上のように表すことができます。
総積なので、総和の\(\sum\)とは異なります。
このままでは解けないので、対数をとり、対数尤度関数を作ります。
$$logL(\theta;x_{i})=\sum_{i=0}^Nlogf(x_{i}|\theta)$$
便利なことに、対数をとると、掛け算は足し算の形になります。ここで、最大化問題を解きます。
\(\theta\)に関して微分を行い、ゼロになる時の\(\theta\)が最尤推定量になります。
MLでMax Likelihood(最尤推定量)です。
$$\frac{d}{d\theta}l(\theta;x)=0,\hat{\theta}^{ML}$$
ここまでの話を、動画でサクッと確認したい方はYoutubeをどうぞ
具体例で考える
具体的な例で考えてみましょう。ある地域で生まれた赤ちゃんの性別を調べたところ、10人中7人が男の子でした。このデータから、「この地域で男の子が生まれる確率 $p$ はどれくらいだろう?」と考えます。
この $p$ が、私たちが知りたい「パラメータ」です。
このとき、尤度関数 $L(p)$ は、観測されたデータ(10人中7人が男の子)が与えられたときに、パラメータ $p$ がどれくらい「もっともらしいか」を示す関数として定義されます。もし、各出産の性別が独立であると仮定すると、この尤度関数は二項分布の確率質量関数を用いて次のように表せます。
$$L(p) = P(\text{データ} \mid p) = \binom{10}{7} p^7 (1-p)^{10-7}$$
ここで、$\binom{10}{7}$ は10人から7人を選ぶ組み合わせの数です。
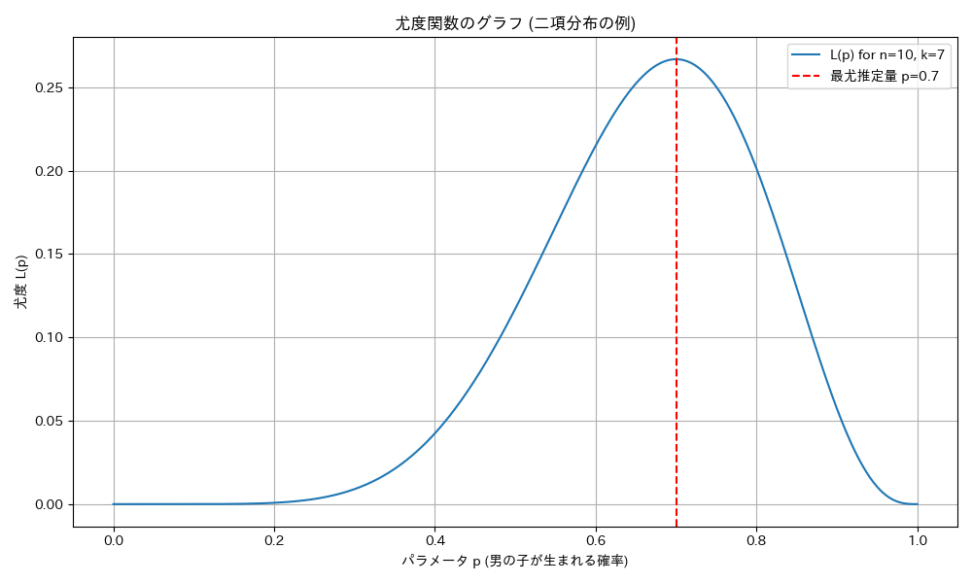
この式は、特定の $p$ の値(例えば $p=0.5$ や $p=0.7$)を代入することで、その $p$ のもとでこのデータが得られる「もっともらしさ」を数値として評価できます。
尤度関数は確率密度関数や確率質量関数と同じ形をしていますが、変数がデータではなくパラメータである点が異なります。また、確率とは異なり、尤度関数の値を全て足し合わせても1になるとは限りません。
このグラフは、様々な $p$ の値に対して尤度 $L(p)$ がどのように変化するかを示しています。尤度が最も高くなる $p$ の値が、観測されたデータにとって最も「もっともらしい」パラメータであると考えることができます。
最尤推定の考え方
尤度関数を理解すれば、最尤法(Maximum Likelihood Estimation, MLE)の考え方はシンプルです。最尤法とは、「観測されたデータが最も『もっともらしく』なるような、統計モデルのパラメータを推定する方法」です。つまり、尤度関数を最大にするパラメータの値を見つけることが、最尤法の目的となります。
先ほどの赤ちゃんの性別の例で言えば、尤度関数 $L(p) = \binom{10}{7} p^7 (1-p)^{10-7}$ を最大にする $p$ の値を探すことになります。直感的には、10人中7人が男の子だったのだから、$p=0.7$ が最も「もっともらしい」と感じるかもしれません。最尤法は、この直感を数学的に裏付ける方法と言えます。
最尤推定量の導出
尤度関数を最大化するためには、通常、微分を用いて最大値を求めます。しかし、尤度関数は積の形になることが多く、そのまま微分すると計算が複雑になることがあります。そこで、対数尤度関数(log-likelihood function)を用いるのが一般的です。対数関数は単調増加関数であるため、尤度関数を最大化することと、対数尤度関数を最大化することは同義です。
対数尤度関数は、尤度関数の自然対数を取ったものです。積の形が和の形になるため、微分が容易になります。
$$\log L(p) = \log \left( \binom{10}{7} p^7 (1-p)^{10-7} \right)$$
$$= \log \binom{10}{7} + 7 \log p + 3 \log (1-p)$$
この対数尤度関数を $p$ で微分し、その結果を0と置くことで、対数尤度関数を最大にする $p$ の値(最尤推定量)を求めることができます。
$$\frac{d}{dp} \log L(p) = \frac{7}{p} – \frac{3}{1-p} = 0$$
これを解くと、$7(1-p) = 3p \Rightarrow 7 – 7p = 3p \Rightarrow 7 = 10p \Rightarrow p = 0.7$ となります。
やはり直感通り、$p=0.7$ が最尤推定量となりました。
最尤推定量の統計学的特徴
最尤推定とは、「我々が観測している現実の標本は、確率が最大のものが実現している」という考えからきています。
最尤推定量は以下のような特徴があります。
①一致性をもつ。
nが十分に大きいとき、推定量が真の値と同値になるということですね。
②漸近正規性を持つ。
nが十分に大きいとき、最尤推定量は正規分布で近似できます。
サンプル数の平方根と残差の積が正規分布に従うという性質があるということですね。
$$\sqrt{n}(\hat{\theta}^{ML}-\theta)\approx N(0,\frac{1}{I(\theta)})$$
\(I(\theta)\)はフィッシャー情報量と呼びます。
フィッシャー情報量とは?
確率密度に対数をとり、微分したものを二乗した期待値です。
$$I(θ)=E[(\frac{d}{d\theta}logf(X_{1};\theta))^2]$$
また、細かいですが、以下の不等式をクラメール・ラオの不等式と呼びます。
つまりフィッシャー情報量が大きいほど推定量の誤差の期待値の下限は小さくなります。
$$E[\hat{\theta}-\theta]≧\frac{1}{nI(\theta)}$$
③不変性を持つ
よく聞く不偏性ではありません。
この不変性は、「関数自体g(θ)の最尤推定量が、θの最尤推定量を代入した形で求められる」ということです。
非常に便利な性質です。
$$g(\theta)^{ML}=g(\theta^{ML})$$
最尤法は、情報量基準の計算で使われています。
モデル選択にどう使われているのか知りたい方は以下のコンテンツをご覧ください。
最尤推定量の欠点
最尤推定量の欠点は以下の3点が挙げられます。
- 計算量が膨大になる場合が多い。
- 密度関数を最大化するので、数理最適化の式を解く必要があります。
- 外れ値に弱い
- 外れ値に対して適切な処理をしていない場合、大きく影響を受けます。
- 分散が過小評価される
- サンプル数が大きくなれば、この問題は軽減されていきます。
- ただ、この欠点が過学習(overfitting)を生む原因であります。
最尤推定量には、不偏性(推定量の期待値が真の値になる)がありませんが、データ量を増やせば、一致性や漸近性などのそれに近い状態を得られるため、問題視されることは少ないです。
$$E[\sigma_{ML}]=\frac{N-1}{N} \sigma^2$$
不偏性については以下のコンテンツで学習してください。


練習問題
問題1
\(X_{i} (i=1〜n)\) がベルヌーイ分布 \(Ber(p)\) に従う時、パラメーター\(p\)を最尤推定しましょう。
【解説】
ベルヌーイ分布の確率分布関数は以下の通りです。
$$f(x|p)=p^{x}(1-p)^{1-x}$$
では、同時確率をとって尤度関数を作りましょう。
$$L(p;x)=\prod_{i=0}^{N}p^{x_{i}}(1-p)^{1-x_{i}}$$
積は、指数で言うと和になりますので、比較的計算は楽かもしれません。
$$L(p;x)=p^{n\overline{x}}(1-p)^{n(1-\overline{x})}$$
平均値にサンプル数nをかけたもので表しています。
では、対数尤度関数を作りましょう。
$$l(p;x)=n\overline{x}log(p)+n(1-\overline{x})log(1-p)$$
このように和の形になりました。
次は、pに関して微分してイコール0を取ります。
\(log\)の微分を思い出しましょう。
分数になります。
$$\frac{n\overline{x}}{p}+n(1-\overline{x})\frac{1}{1-p}=0$$
この方程式の解である、\(\theta\)が最尤推定量になります。
計算は省きますが、xの標本平均になります
$$\hat{p}^{ML}=\overline{x}$$


問題2
\(X_{i} (i=1〜n)\) がポアソン分布 Po(λ) に従う時、パラメーター\(\lambda\)を最尤推定しましょう。
【解説】
まずは、ポアソン分布の確率分布を見てみましょう。
$$f(x|\lambda)=\frac{\lambda^x}{x!}e^{-\lambda}$$
\(\lambda\)が生起率でした。
では肝心の尤度関数を求めてみましょう。
$$L(x|\lambda)=\prod_{i=0}^{N}\frac{\lambda^{x_{i}}}{x_{i}!}e^{-\lambda}$$
では対数尤度関数を作ります。
対数をとると、割り算は引き算になります。
$$l(λ,x)=(\sum_{i=0}^{N}x_{i})logλ-log(x_{1}!…x_{n}!)-n\lambda$$
第二項に厄介そうな数式がありますが、これは後で\(\lambda\)に関して微分した時に0になるので問題ありません。
では、λに関する最大化問題を解きます。
$$\frac{\partial l(\lambda;x)}{\partial \lambda}=(\sum_{i=0}^{N}x_{i})\frac{1}{\lambda}-n=0$$
求める推定量は、\(\lambda\)です。
\(\lambda\)についての方程式を解くと以下のようになります。
$$\hat{\lambda}^{ML}=\overline{x}$$
結局こちらも標本平均でした。


おまけ|尤度とベイズ統計の関係
これまでの議論で、尤度はあるデータが与えられた条件下で、パラメータの特定の値がどれほど適合するかを表す指標だということがわかりましたね。
この尤度の性質を使って「事前確率を更新する」のがベイズ統計の基本となります。
高校数学でも見たことがあるかもしれませんが、ベイズの定理をまず確認しましょう。
$$P(\theta|X) = \frac{P(X|\theta) * P(\theta)}{P(X)}$$
\(P(\theta|X)\) : データが与えられた条件下で\(\theta\)が発生する確率(事後確率)
\(P(X|\theta)\) :\(\theta\)が与えられた条件下で Xが発生する確率(尤度)
\(P(\theta)\) :\(\theta\)が発生する確率(事前確率)
\(P(X)\) :データが発生する確率(周辺確率)です。
ベイズの定理は、尤度と事前確率を用いて、データが観察された後のパラメータの確率(事後確率)を更新する方法を提供します。
すなわち、事前確率に尤度を掛け、その結果を周辺確率で割ることで、事後確率を計算することができます。
確率分布に関しても同様の議論ができ、事前分布に尤度をかけても事後分布の分布族が事前分布と一緒になることを「尤度と事前分布が共役な関係にある」と呼びます。
ベイズの定理から考えると、事後分布は事前分布\(w(\theta)\)と尤度$${f(z|\theta)}$$の積に比例します。
ベイズ更新を何度も行う関係で、事前分布の形が複雑だと事後分布の形もどんどん複雑になることがわかります。
そこで、共役な関係があると嬉しいということですね。
$${w'(\theta|z)=\frac{w(\theta)f(z|\theta)}{\int_{\Theta}w(\theta)f(z|\theta)d\Theta} \propto w(\theta)f(z|\theta)}$$
ベイズの定理に関しては、こちらの記事でより平易に説明しております。
最尤法とMAP推定(最大事後確率推定)について
例えばデータが少ない時のように、最尤法だとパラメータが信頼できません。
そのデータがまれにしか得られないデータかもしれないからですね。
そこで、与えられたデータに基づいて事後分布を最大化するパラメータの値を見つけるアプローチをMAP推定と呼びます。
$$\hat{\theta}_{MAP}=argmax_{\theta}p(\theta|D)=argmax_{\theta}p(D|\theta)p(\theta)$$
上の式で見るとわかりやすいですね。
最尤法だと、あるパラメータが与えられた時にデータが得られる確率(これを尤度と呼びます)\(p(D|\theta)\)が、最大化されます。
さて少し踏み込んだ内容になりますが、一般に考慮すべきパラメータ空間が大きい場合や尤度関数が複雑な場合は周辺確率\(P(X)\)の計算が困難な場合があります。
\(P(X) = \int P(X|\theta)P(\theta) d\theta\) (連続パラメータの場合 )
\( P(X) = \sum P(X|\theta)P(\theta)\) (離散パラメータの場合)
そのような場合には一般的にMCMC法(マルコフ連鎖モンテカルロ法)などの事後分布を近似した分布からサンプリングを行う方法などが使われます。



青の統計学は、東京大学を卒業後、事業会社でデータサイエンティストとして勤務する筆者が運営する、AI・データサイエンスの総合学習メディアです。 自身の大学時代の経験から、教科書だと分かりにくかった事項を克服でき、かつ実務で活かせる知識を楽しく学べるように、インタラクティブ学習ツール「DS Playground」を開発しており、大学での講義の材料としても利用されています。Xフォロワー1万人を突破!

