【高校生向け】③分散のn倍問題(Lv.共通テスト)
共通テストには、「分散Wをn倍した時に、分散Zは何倍になるか(もしくは変わらない)」という問題がよく出ます。例題を通してみてみましょう。
今回は政府統計の、平成20年度学校保健調査の都道府県別「5歳から17歳の男子平均身長と平均体重」を参考にしました。
また末尾に問題で扱った表や式の作り方についてまとめています。
【例題】
政府統計の5歳から17歳までの身長と体重のデータを分析した結果、以下のような式が得られた。Yは身長でZは体重とします。
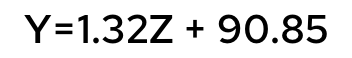
(1)Yの分散はZの分散の何倍でしょうか。
(2)体重に関して、キログラムではなくポンド(P)で考えるとする。P=2.2Zとする。この時、Y(身長)とZ(kg)の相関係数は、Y(身長)とP(ポンド)の相関係数の何倍でしょうか。
【解説】
(1)分散と相関係数の式を考えてみると問題が解けます。
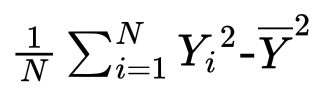
分散は、「2乗の平均から平均の2乗を引く」というものでした。Zを1.32倍して90.85を足したものがYでした。
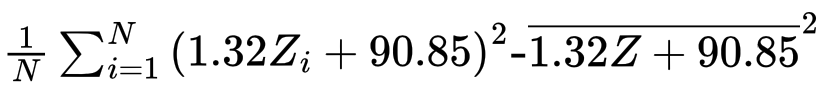
式を直すとこうなりますね。なので、Yの分散は、Zの分散の1.32の2乗倍になります。よって、1.7424倍です。
(2)YとPの相関係数はこのような式になります。YとPの標準偏差の積が分母で、共分散が分子でした。
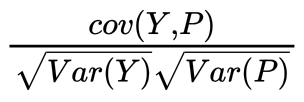
では、P=2.2Zの時にはどうなるでしょうか。
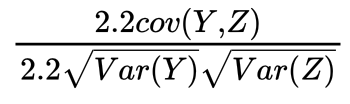
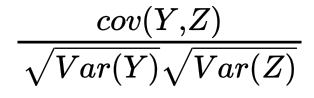
このように、分子にも分母にも2.2が出てくることで、約分されて相関係数の値は変わらないことがわかります。よって答えは、1倍です。
【どうやってこの問題を作ったか】
この問題をどう作ったか知りたい方は、以下をご覧ください。プログラミングに慣れて仕舞えば、ご自分でも作れると思います。
政府統計の表を一部抜粋してみます。
| /身長・体重・座高 | 身長(cm) | 身長(cm) | 体重(kg) | 体重(kg) | 座高(cm) | 座高(cm) | 身長(cm) | 身長(cm) | 体重(kg) | 体重(kg) | 座高(cm) | 座高(cm) | |
| 都道府県別 | /平均値・標準偏差 | 平均値 | 標準偏差 | 平均値 | 標準偏差 | 平均値 | 標準偏差 | 平均値 | 標準偏差 | 平均値 | 標準偏差 | 平均値 | 標準偏差 |
| 全国 | 110.8 | 4.74 | 19.1 | 2.73 | 62.1 | 2.86 | 109.8 | 4.68 | 18.6 | 2.59 | 61.6 | 2.78 | |
| 北海道 | 111.1 | 4.63 | 19.3 | 2.63 | 62.4 | 2.85 | 110.2 | 4.60 | 19.0 | 2.68 | 61.9 | 2.89 | |
| 青森県 | 111.7 | 4.74 | 19.7 | 3.05 | 62.7 | 2.62 | 110.2 | 4.56 | 19.1 | 2.81 | 61.9 | 2.51 | |
| 岩手県 | 111.5 | 4.41 | 19.7 | 3.41 | 62.1 | 3.32 | 110.5 | 4.79 | 19.1 | 2.98 | 61.6 | 3.22 | |
| 宮城県 | 111.3 | 4.73 | 19.7 | 2.93 | 62.4 | 2.82 | 110.4 | 4.78 | 19.4 | 2.69 | 62.2 | 2.86 | |
| 秋田県 | 112.1 | 4.91 | 19.8 | 3.32 | 62.6 | 3.14 | 111.2 | 4.77 | 19.5 | 2.81 | 62.1 | 3.06 | |
| 山形県 | 111.4 | 4.95 | 19.6 | 3.22 | 62.5 | 2.85 | 110.4 | 4.67 | 19.0 | 2.73 | 62.0 | 2.73 |
表をRに入れて、必要なデータだけ使うこととします。
x<-read.csv("FEH_00400002_220519155324.csv",header=T,fileEncoding = "CP932")
#fileEncoding = "utf-8"ではエラーになりました。
y<-x[,4]
#4列目が男子の平均身長
y<-y[-1:-2]
#1番目と2番目は「身長(cm)」「平均値」なのでいらないです。3行目以降のみをベクトルに入れます。
z<-x[,6]
#6列目が男子の平均体重
z<-z[-1:-2]
#1番目と2番目は「体重(kg)」「平均値」なのでいらないです。3行目以降のみをベクトルに入れます。
列番号や行番号に-をつけると、行列から削除することができます。ここでは、「身長」や「体重」などの列名はグラフには必要ないので削除しましょう。このままでは”172.2”のように文字列なので、実数型に変更しましょう。
y<-as.double(y)
y
#各値を小数型に変換しましょう
z<-as.double(z)
z
#各値を小数型に変換しましょう
par(family = "HiraKakuProN-W3")
plot(y,z,xlab = "身長",ylab = "体重",main="平成20年度男子の身長と体重の関係",pch=20)
#表を作ってみましょう
par(family = “HiraKakuProN-W3”)を記入しないとグラフで日本語が出力できません。pch=に関しては1から25まで種類が取れます。デフォルトは1(○)です。今回は、データが多すぎるので、小さめの黒丸に変えました。以下が出力したグラフです。
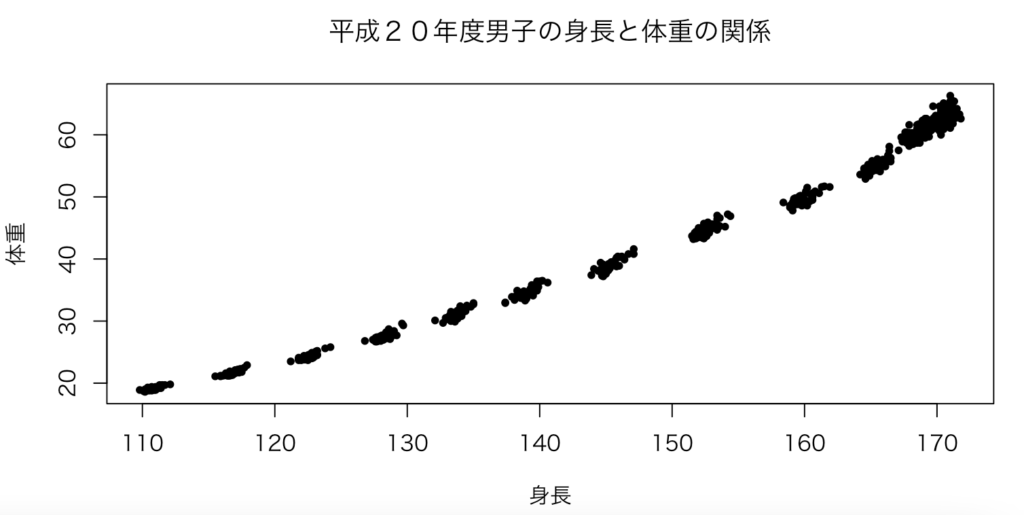
グラフを見てみると、160cmあたりから急に体重が増えてますね。興味深いです。女子生徒の身長と体重でも実験してみると面白いかもしれません。成長期に男女差があるのかの考察に繋がりそうです。
では、問題で指定した式の作り方についてです。
liner<-lm(y ~ z)
summary(liner)
lm()は、y=ax + bの形で線形回帰を行うコマンドです。

上のような結果が出ました。interceptで切片が90.84587、zの係数の推定値が1.32168となりました。この政府統計のデータでは、
身長 = 1.32168 × 体重 + 90.84587 という推定結果が出ました。
四捨五入をして、問題ではY = 1.32 Z +90.85としたということです。
他にも「データの活用」の問題を解きたい方は、以下のコンテンツをご覧ください。
【高校生向け】データの活用の例題①(Lv共通テスト)
【高校生向け】データの活用の例題②(Lv共通テスト)
【高校数学I】分散と標準偏差とは?(Lv.定期テスト)

